-
[논문 리뷰] Auto-Encoding Variational Bayes - VAE논문 리뷰 2024. 8. 27. 13:31
[논문링크]
Auto-Encoding Variational Bayes
[세줄 요약]
VAE는 sample 분포에서 생성하고자 하는 모델이다.
Intractable한 p(x),p(x|z)를 근사하기 위해 q(z|x)인 encoder를 도입하였다.
역전파가 가능하게끔, ELBO, Reparameterization trick를 사용하였다.
참고)
논문만 보고 이해하기가 좀 어렵다. 그래서 논문에 담겨져 있지 않은 기본적인 지식과 함께 다루고 있으니, 완전히 논문와 순서가 똑같지는 않을 수도 있다.
참고하면 좋을 영상들)
0. Abstract
이 논문의 목표는 다음과 같다.
How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets?
잠재변수로 이루어진 확률분포(연속적인 latent variable)에서 사후 분포를 모를 때 어떻게 학습할 수 있는가? 이다.
즉, 내가 모르는 분포(고양이 사진 확률분포)를 출력하고 싶은데, 어떻게 잠재변수 확률분포에서 sampling 할 수 있는가? 에 대한 문제이다.
논문에서는 2가지로 기여하였다고 소개한다.
1) reparameterization of the variational lower bound 방법을 소개하였다.
Reparameterization을 통해 standard stochastic gradient method를 적용할 수 있게 되었다.
2) Apporoximate inference model( recognition model) 를 도입하였다.
Encoder를 만들어서 intractable한 확률분포를 효율적으로 학습할 수 있게 되었다.
1. Introduction
기본적으로 이 VAE의 태생적인 목적은 생성하는 모델이다!
예를 들어 고양이 사진의 잠재변수 분포가 있다고 할 때, 이를 기반으로 다양한 고양이 사진을 생성하고자 하는 것이 목표이다.
하지만 이에 따라 여러가지 문제들이 있기 때문에(고양이 분포를 모른다. 등등..) encoder의 개념을 들고 온 것이다.
여기서 풀고자하는 문제를 더 상세히 정의하면, sampling하고자하는 확률분포를 학습할 때, intractable한 사후분포를 가진 잠재변수나 파라미터라면 이를 어떻게 학습할 수 있는가? 이다.
p(x|z)가 intractable하다는 뜻 이라고도 볼 수 있다.
Intractable한 사후분포 p(x|z)를 추론하기 위해 reparameterization of the variational lower bound 기법을 사용하여 SGVB를 통해 사후분포에 근접한 분포를 추론하고자 한다. 방법론적인 것은 후에 다루도록 하겠다.
간략하게 Autoencoder vs VAE를 하고자한다.
목표:
AE: latent vector를 잘 만드는 것이 목표
VAE: latent vector에서 원하는 이미지를 만드는 것이 목표Latent vector의 값:
AE: 특정한 값
VAE: 확률분포 , 왜냐하면 결국 sampling하기 위해서는 확률분포를 만들어야지 확률분포에서 생성하기 때문이다.
2. Method
2.1 Problem scenario
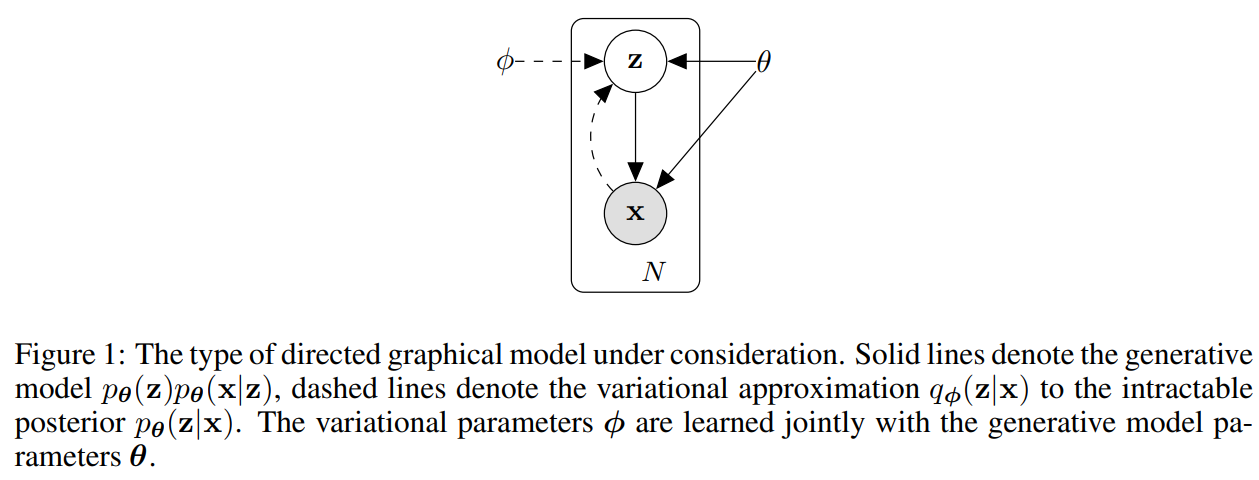

가정부터 살펴보자.
x: 연속적 or 이산적 변수
z: 랜덤한 연속적인 변수, z에 의해 x를 생성한다.
1) z는 사전분포 p(z)에서 생성된다.
2) x는 p(x|z)를 통해 생성된다.
여기서 결국 p(z), p(x|z)를 모르기 때문에, 이를 알아내야 한다.
목표로 하고자 상황은 다음과 같다.
1) p(x)가 intractable할 때를 알고자한다. 즉 marginal or posterior probabilities 또한 잘 모를 때이다.
이는 고양이 사진 데이터의 확률분포를 모른다는 예시를 들 수 있다.
2) Large dataset 에도 적용 가능해야 한다.
MonteCarlo EM의 경우 여러번의 minibatch를 통해 계산하는데, batch 최적화가 되지 않을 정도로 계산량이 많은 데이터에도 적용 가능해야 한다.
이러한 시나리오에서 알고자하는 것은 다음과 같다.
1) parameter θ에 대한 학습
2) pθ(z|x) 사후 확률 분포 추정하기
3) pθ(x) 추정하기
VAE의 접근방식이 여기서 드러난다. pθ(z|x), pθ(x) 둘 다 모르기 때문에 encoder를 도입한다!
recognition model qφ(z|x)를 도입한다. 이는 pθ(z|x)를 근사한다고 가정한다.
이로써 qφ(z|x)인 probabilistic encoder와 pθ(z|x)인 probabilistic decoder를 설정하게 된다.
쉽게 이해하자면 우리는 p(z|x), p(x)를 알고 싶다. 하지만 사실 p(z)도 모른다. 근데 바로 p(z)를 가정하기에는 실제 분포를 모르니, p(z|x)를 알자. p(z|x)를 알려면 p(x)도 알아야한다는 다시 처음의 문제에 봉착한다. 그러면 우리는 q(z|x)를 도입해 p(z|x)랑 매우 유사하게 학습한다고 하자! 그리고 그 계산과정에서 여러 기법을 첨가하자! 로 이해할 수 있다.
VAE의 전체 구조이다.

2.2 The variational bound
수식을 전개하기 전에 알면 좋을 개념이다.

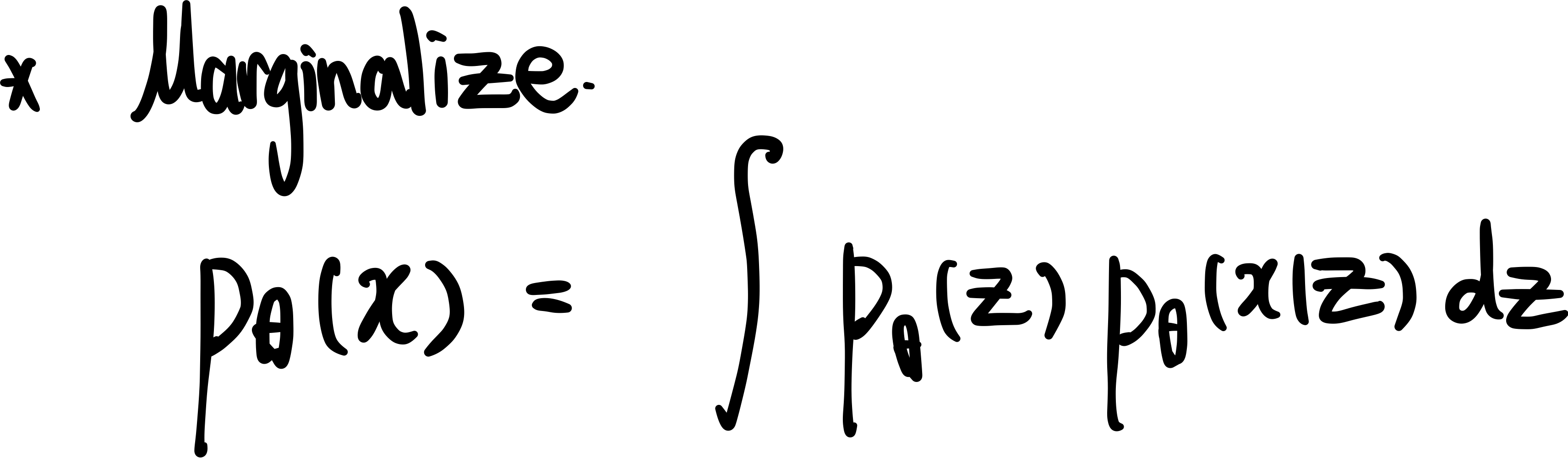


우리의 목표는 pθ(x)를 최대화 하는 것이다.
왜냐하면 z를 통해 생성한 p(x)가 실제랑 유사하면 좋기 때문이다. 우리가 잠재변수로 생성한 p(x)가 실제랑 유사할 수록 좋다.
이를 수식으로 풀면 다음과 같다.
차근차근 수식으로 이해해보자.


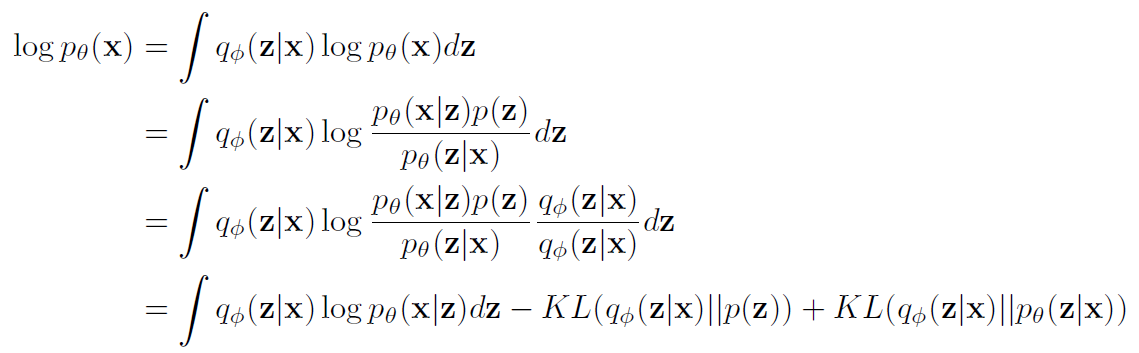
마지막 식이 논문의 equation 1이다.
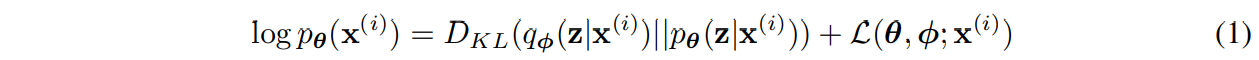
여기서 ELBO가 들어간다.
우리는 하지만 p(z|x)를 모른다. 그렇기 때문에 ELBO를 사용한다.
KL 차이 값은 기본적으로 차이 값이기 때문에 0보다 크거나 같다는 특성이 있다.
따라서 이를 제외하고 남은 값을 계산하고자 한다.
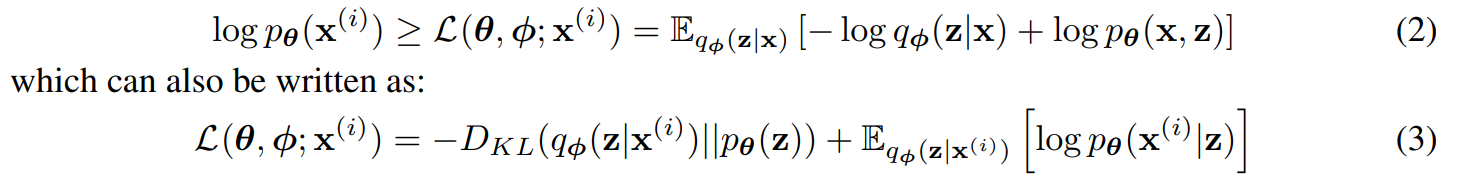
이렇게 남은 수식은 다음과 같이 전개된다.
즉 다음과 같은 variational lower bound(3번식)을 최대화하는 방식으로 학습하게 된다.
Loss function는 위의 수식에 마이너스 취한 값이다.
하지만 여기서 새로운 문제가 발생한다. 바로 gradient를 계산하기 힘들다는 것이다!
주로 이러한 문제가 발생하면 Monte Carlo gradient를 사용한다. 이는 적분계산이 어려울 때 샘플링을 무작위로 여러번 하고 평균을 내는 방식으로 대체하여 계산하는 방법이다.

하지만 이러한 방식은 논문에서 말한 것과 같이 분산이 매우 큰 경우 불안정하다는 단점이 있다.
그래서 새로운 접근법이 필요하다.
바로 reparameterization trick 이다.
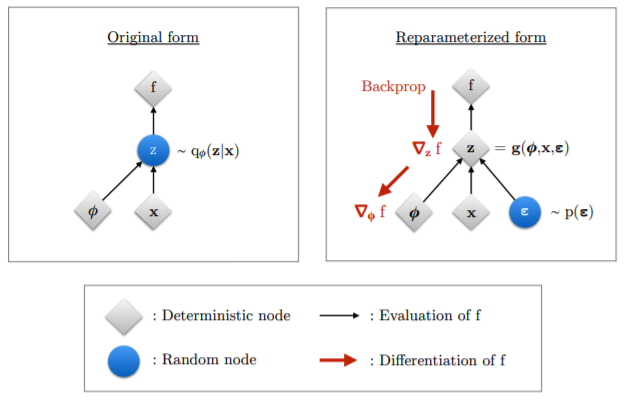
추가적으로 설명하자면, 사실 backpropagation을 할 수가 없다. φ때 encoder에서 sampling 하여 z를 뽑아내는 과정이 있다. sampling하는 것은 확률적인 과정이기 때문에 학습의 영역이 아니다. 따라서 z를 수식으로 나타낼 수 없기 때문에 역전파할 수 없다.
Loss function에 대해 더 깊이 이해해보자!

앞뒤 항을 바꾸면
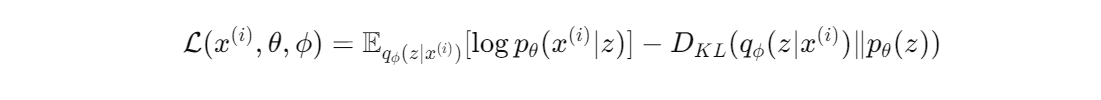
여기서 앞의 항을 Reconstruction error 뒤의 항을 Regularization error라고 한다.
Reconsturction Error : 원본처럼 얼마나 잘 생성하는가?
encoder를 거쳐 다시 decoder를 거칠 때 생성되는 x가 원본과 유사한가? 를 말한다.
encoder한 z가 x를 잘 표현하는가 라고 이해할 수도 있다.
Regularization Error : z가 사전분포 p(z)랑 유사한가?
사전분포 p(z)와 q(z|x)가 유사한가를 말한다.
우리가 만든 z가 우리가 가정한 p(z)랑 유사하여 잘 생성하도록 분포를 만들어 내는 가 라고 이해할 수 있다. 즉 가우시안 분포랑 유사한가라고 생각할 수 있다.
2.3 The SGVB estimator and AEVB algorithm
SGVB: Stochastic Gradient Variational Bayes
ELBO를 추정하여, gradient를 계산하는 방법이다.
AEVB: Auto-Encoding VB
VAE 알고리즘으로 p(z|x)를 q(z|x)로 근사하여 encoder decoder 전체를 학습시키는 과정이다.
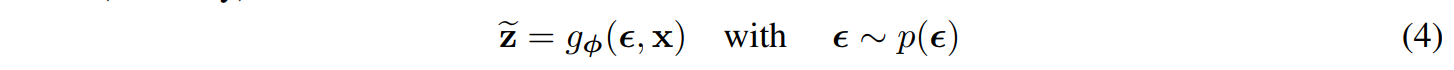
직접 z에서 역전파하는 것이 불가능하므로 z의 분포를 reparameterization 한다.
Noise를 추가하는 방식으로 분포를 구성하게 한다. 이는 복잡한 분포인 q(z|x)에서 sampling하는 것이 아니라, p(ϵ)에서 sampling하는 방식으로 바꿔 더 계산을 간단히 한다.
이를 기반으로 Monte Carlo 추정을 적용한다.
여기서 두 가지 방식을 적용할 수 있다. 모든 항에 적용하거나, 계산할 수 있는 항은 남겨도 적용하는 방식이다.
두 가지 항 중 둘다 적용하거나 하나만 적용하거나 
이는 뒤의 항에만 적용한 식이다. 첫번째 식은 다음과 같다.

이는 두개의 항에 모두 적용했을 때의 식이다. 하지만 KL divergence의 경우 식을 계산할 수 있다.
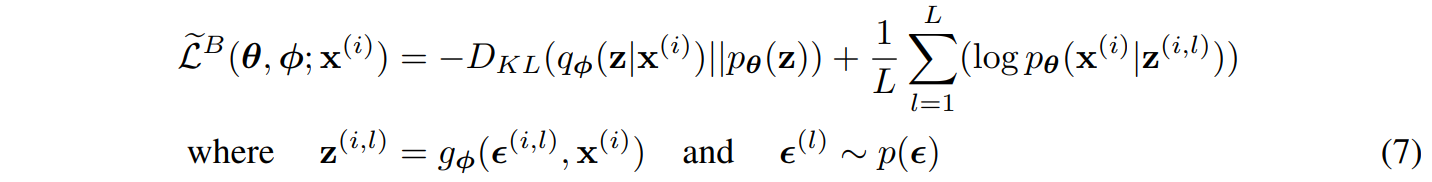
뒤의 항에만 적용했을 때 식이다. 다음과 같이 적용할 수 있다.
이는 이제 gradient를 계산할 수 있도록 적용된 식이다.
2.4 The reparameterization trick
재매개변수화 변수를 사용하므로써 Monte Carlo estimate를 통해 미분 가능할 수 있게 되었다.

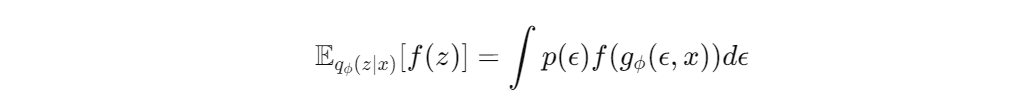
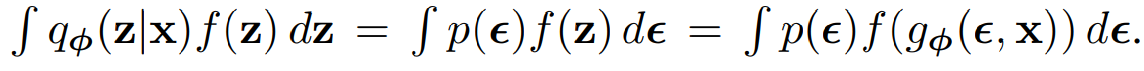
이렇게 변환이 가능하다.
q(z|x) 대신에 새로운 분포에서 뽑아내는 방식으로 sampling하는 방식이 미분 가능해졌다.
예를 들어)
z ∼ p(z|x) = N (µ, σ2 ) 라는 분포에서 sampling하고자 한다.z = µ + σ ϵ 로 재매개변수화 할 수 있다. 이 때 ϵ ∼ N (0, 1)에서 추출된다.
따라서 식을 다시 전개하면
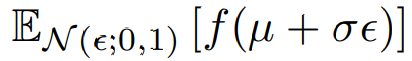
이렇게 전개할 수 있다.
추가적으로 어떤 식일 때 어떻게 noise를 뽑아야 되는지 논문에 추가적으로 설명되어있다.
Noise를 추가한다는 것의 의미)
sampling을 하기 위해서는 encoder 된 값이 가우시안 분포에 가까워져야 한다!
그래서 encoder가 가우시안 분포로 가깝게 학습하면 생성이 잘 안된다. 왜냐하면 학습과 sampling의 차이 때문이다. 실제로는 가우시안 분포에서 생성하는 것이 아니기 때문이다. 가우시안은 우리가 생성하기 쉽게 끔 가정한 확률 분포이다. 실제는 더 특이할 것이다. 즉 목적으로 한 loss function는 재복원만 잘하면 되는 것이지, 결코 생성을 잘하라는 것이 아니라는 점이다. 그렇기 떄문에 Noise를 추가한다.
즉 encoding 한것에 어느정도를 noise를 더해서 가우시안에서 sampling 한 것과 유사하게 끔 하는 것이다.
3. Example Variational Auto-Encoder
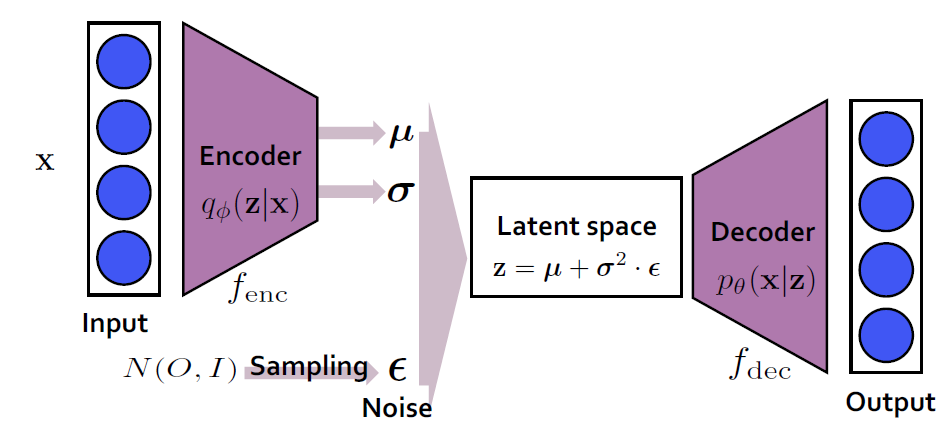
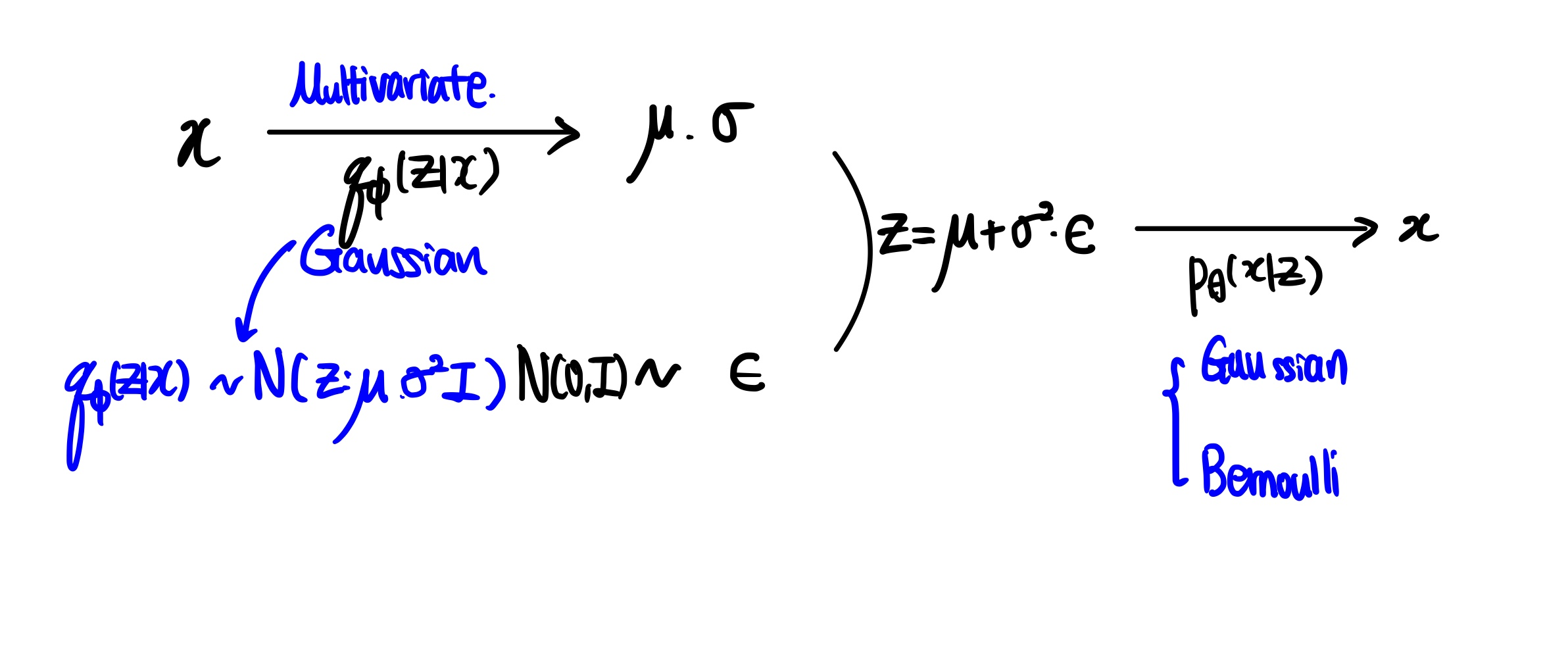
µ, σ가 encoder MLP의 출력이다. 그리고 encoder, decoder, prior distribution의 분포에 따라 실제 계산 수식이 달라진다.
가정)
p(z): N(o,I) Gaussian, multivariate normal distribution
q(z|x): Gaussian, 대각공분산, multibariate normal distribution with diagonal convariance N (z; µ (i) ,σ 2(i) I)
p(x|z): Gaussian or Bernoulli
이면.
KL는 가우시안 분포 사이의 계산이기 때문에 계산 가능하다. (appendix B에 gaussian 분포끼리의 KLD를 계산해준다.) 즉 수식7번의 KLD를 실제 코드에 적용하기 위한 식 전개라고 이해하면 된다.

라는 식을 참고하면 이해에 도움이 된다.
진짜 식 전개 및 대입이다.
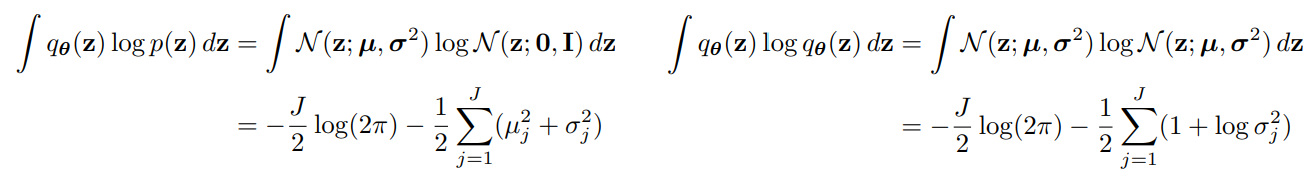
여기에 대입하여 전개한 식이라고 한다.. 
이제 우리가 가우시안 분포의 차이를 해석한 식이 보인다!

다음과 같이 정리할 수 있다.
이제 p(x|z)가 베르누이인지 가우시안에 따라 뒤에 reconstruction error 또한 계산할 수 있다.


다음과 같이 베르누이인지 가우시안인지에 따라 식이 전개된다.
그래서 가우시안 분포일 때, 최종식은 다음과 같이 볼 수 있다!
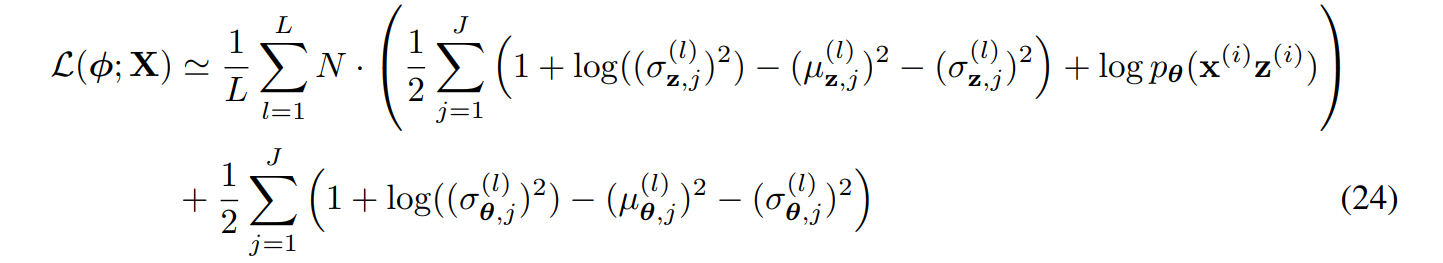
4. Experiments
Dataset: MNIST, Frey Face dataset



AEVB가 Wake sleep 보다 높은 Marginal likelihood가 높게 나왔다.(더 높은 ELBO 값를 더 빠르게 수렴)
'논문 리뷰' 카테고리의 다른 글