-
[논문 리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale - ViT논문 리뷰 2024. 8. 12. 14:10
[논문 링크]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[세줄 요약]
Transformer를 Image에 적용한 사례임.
Patch로 분할하여 sequence token처럼 고려해 transformer에 적용하였음.
Large dataset에 sota의 성능을 보이며, fine tuning하여 사용할 수 있음.
0.Abstract
Vision 분야에서는 attention이 CNN과 결합해서 지금까지 사용되었다. Image Patch를 sequence로 적용하는 방식으로 transformer 만을 순수하게 사용한 Vision Transformer(ViT) architecture를 만들었다. Large data를 pretrain하고, mid-sized, small data를 transfer하는 방식으로 SOTA의 성능을 보였다.
1. Introduction
Computer vision 분야에서는 아직 CNN architecture를 사용했었다. ResNet이 아직 SOTA인 상황이다.
Transformer를 적용하기 위해서 Image를 Patch로 나누고, sequence를 부여해서 transformer에 input하는 방식으로 처리하였다.
we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application.
Transformer 가 CNN에 비해 inductive bias가 낮아서, mid-sized dataset 학습에서는 ResNet보다 낮은 정확도를 보였지만, large dataset에서는 SOTA의 성능을 보였다.
Inductive bias란?
모델이 학습할 때 기존의 설정된 가정으로 일반화할 수 있는 정도를 의미한다.
Inductive bias가 낮다는 것은 data의 양이 적을 때, generialized 되는 정도가 낮다는 것을 의미한다.
논문에서는 CNN과 비교할 때 translation equivariance와 locality를 예시로 설명한다.
Translation equivariance: 어떤 특징의 위치나 각도가 바뀌어도 그 특징을 동일하게 인식하는 능력
Locality: 모델의 작은 영역에서 특징을 찾아내는 능력
Translation equivariance and locality 가 낮다는 것은 Generalized하는 능력이 낮아, inductive bias가 낮다고 해석할 수 있다. Vit에서는 CNN과 비교했을 때 이러한 한계를 극복하기 위해 여러 장치를 설정을 한다. 이는 뒤에 설명할 예정이다.
2. Related Work
Transformer를 Image에 적용하려고 한 여러 선행 연구들이 정리되어있다.
Self attention를 모든 pixel과 pixel에 적용한 논문이 있었다. 이는 Cost가 너무 높았다. 그래서 모든 pixel에 적용한 것이 아니라 query pixel에만 적용한 경우도 있었다. 다양한 크기의 block에 scale attention을 적용한 논문 또한 있다.
2x2 patch를 사용하여 full self attention을 적용한 논문도 있다. CNN와 self attention을 결합한 논문 또한 있다. 그리고 image resoliton과 color space를 줄이고 transformer를 image pixel에 적용한 iGPT도 있다.
3. Method
3.1 Vision Transformer(ViT)

Vit의 전체 model 구조이다. 수식으로 들어가기 전에 직접 구조를 이해해보자.
Step1. 2D patch로 분할하기

HxWxC image를 2D image patch로 분할한다.

HxWxC 를 Nx(PxPxC)로 분할 한다.
H,W: 원본 image의 resolution
C : channel의 수
N: patch의 갯수
P: image patch의 resolution

N = HxW/(PxP) 이다.
이는 위의 그림을 보면 만약 원본 image 48x48 일 때, 16x16의 patch로 분할할 때 가로 세로 3개씩 총 9개의 patch가 만들어지는 것을 쉽게 생각할 수 있다.
Step2. 2D patch를 1D embedding로 Flatting 하기

Latent vector D 차원으로 변환하면서 1차원으로 Flatting하는 작업을 진행한다. 이는 Linear projection을 통해 진행하게 된다. 즉 Weight(엄밀히 볼 때는 1x(PxPxC)차원)를 곱해 1차원으로 flatting한다. 이렇게 1D로 변환하므로써 transformer의 sequence input으로 사용할 첫번째 준비를 마친다.
3. Positional Embedding 추가하기, Class token 추가하기
Transformer encoder로 input하기 전에 선행작업을 몇가지 거친다.
1) Postional embedding 더하기
일단 transformer랑 마찬가지로 postional embedding을 추가한다. Image인 만큼 2D aware postional embedding을 사용할 수 있지만, 성능 차이가 보이지 않아 1D postional embedding을 사용하였다. 이처럼 구한 postional embedding은 patch embedding과 더해서 사용하게 된다.

어떠한 postional embedding이 효과적인지 비교한 figure이다. 논문에서는 여러 가설을 설정하여 실험하였다. 1D(순서만 고려), 2D(x,y까지 고려), Relative(상대적 관계를 표현)하는 embedding방식들, input할 때 encoder 전에 input할지, 중간 layer에 할지 등 여러 방식이 있었다. 하지만 결국 postional embedding을 하는 것이 중요할 뿐 어떠한 방식이 유의미한지에는 큰 차이가 없었다. 논문에서는 patch로 분할하는 것이 pixel 같이 작은 단위보다 이미 어느정도 공간적 정보가 담겨져있기 때문에 위치 임베딩의 방법이 덜 중요해졌다고 이야기한다.
2) Class token 추가하기
BERT의 아이디어를 빌려서, [Class] embedding을 추가로 설정한다. [Class] token은 sequence의 맨 앞에 추가하게 되는데, 그 image representation을 나타내는 token으로 사용한다. Transformer encoder를 거치고, pretraining 할 때는 MLP(one hidden layer)를 거친 후, fine tuning할 때는 single linear layer를 거친 후 classification 작업을 진행하는데 사용할 수 있다.
4. Transformer Encoder(MSA, MLP, LN)

Multiheaded self attention(MSA), MLP, Layernorm(LN), residual connection이 기존의 transformer encoder랑 유사하게 적용하게 된다.
차이점은 모델 구조를 보면, LN layer가 MSA layer과 MLP layer 전에 적용하게 된다는 것이다.
그 이유로는 논문에서 확인하지 못했지만,(다른 논문을 인용했음) LN이 전체적인 데이터 분포를 안정화시켜 MSA에 들어갈 때 왜곡되는 정도를 낮추는 정도로 이해했다.
수식은 다음과 같다.

(1) Image patch x과 Weight E를 곱하여 1D embedding 으로 변환하는 수식이다. 맨 앞에 class token과 맨 뒤에 postional embedding이 더해진 것을 확인할 수 있다.
(2) Multihead self attention layer이다. 여기서 LN이 residual connection과 달리 먼저 적용된 모습을 볼 수 있다.
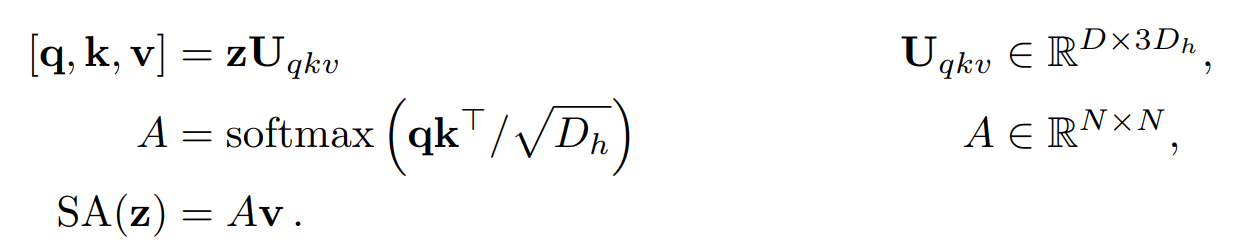
Head까지 고려한 세부 상세식이다. 결국 Transformer랑 똑같다.
(3) MSA랑 똑같지만 MLP를 거친 수식이다.
(4) z0L는 class token x(z00)가 transformer encoder를 통과한 후의 값이다. 마지막에 추가로 MLP를 거쳐 image representation y를 도출한다.
Inductive bias
MLP layer는 local, translationally equivariant한 학습을 진행하지만, self attention layer는 전체적으로 학습하기 때문에 inductive bias를 낮추는 요소이다. CNN에 비해 낮은 inductive bias을 극복하기 위해 다음과 같은 접근을 시도한다.
쉽게 생각해서 CNN에 비해 이미지 안의 공간적 관계를 더 이해시키기 위한 작업을 해야한다!
Image patch로 분할하는 것은 공간적 관계를 더 쉽게 이해할 수 있게 한다. Patch 간의 관계 학습을 통해 공간적 관계를 더 이해할 수 있다.
Fine tuning 시 다른 resolution 간의 postional embedding를 조정하는 것은 공간적 관계를 더 쉽게 이해할 수 있게 한다. Fine tuning 시 해상도가 기존의 것과 완전히 같지 않을 것이다. 크기가 다른 image 간에서 postional embedding을 사용하는 것은 일관성이 생길 기준을 만들어줘서 해상도가 다른 이미지 간의 공간적 관계를 더 이해할 수 있게 해준다.
Postional embedding에 대해 더 깊게 들어가자면, 엄밀하게 postional embedding은 image patch간의 공간적 관계에 대한 정보를 초기에 가지고 있지 않는다. 그냥 sequence 순서만을 나타낸다. 그렇기 때문에 공간적 관계는 transformer를 거치면서 학습해야 되는 정보이다.
Hybrid Architecture
CNN를 거친 feature map을 patch embedding으로 사용하는 hybrid model의 경우 이미 feature map에 공간적 관계 정보가 포함되어있기 때문에 patch의 크기을 1x1로 사용할 수 있다.
3.2 Fine tuning and higher resolution
Large data set으로 pretrain하고, Small dataset으로 finetuning 한다.
보통 finetuning할 때는 더 고해상도의 image로 같은 size patch를 사용한다.
finetuning할 때 고해상도로 쓰면 patch length가 길어지기 때문에 postional embedding을 다시 조정하는 2D interpolation 작업을 진행해야 한다.
4. Experiments
Dataset: ImageNet 1K 1.3M image, Image Net 21k 14M image, JFT 18k 303M image

ViT model이 SOTA의 성능과 낮은 cost를 보인 것을 확인할 수 있다.

그리고 적은 dataset보다 large dataset에 좋은 성능을 보인 것을 확인할 수 있다.
Inspecting Vision Transformer

Left)
Linear projection을 통해 flattening하는 과정을 거칠 때 embedding filter를 거치게 된다. Embedding filter는 linear projection할 때의 가중치 weight라고 생각하면 된다. 이러한 embedding filter는 학습되면서 그 patch의 top principal component(주요한 부분)을 학습하게 된다. Embedding filter를 거치면서 저차원으로 변환되지만, 그 주요한 특징을 잘 대표하는 것을 확인할 수 있다.(low dimensioanl representation of the fine structure within each patch)
Center)
Positional embedding의 similarity를 확인할 수 있다. 시각화 자료를 보면 patch간의 거리에 따라 postional encoding의 similarity가 높다는 것을 확인할 수 있다. 또한 유사한 행과 열일 수록 비슷한 postional embedding을 가진 것을 확인할 수 있다.
Right)
Self attention는
Attention distance이라는 개념을 제안했는데, 마치 CNN의 receptive field size 같은 개념이다.
the average distance in image space across which information is integrated based on the attention weights
각각의 patch가 어느정도 멀리있는 정보까지 고려하는 정도 라고 생각하면 된다. Self attention 특성 상 patch 끼리 서로 비교하면서 학습하기 때문에 서로 멀리있는 정보까지 학습한다. 그래프를 보면 확인할 수 있듯이 lowest layer에서도 global하게 학습하는 것을 확인할 수 있다. Head에 따라 attention distance가 다른 것을 확인할 수 있는데 결국 deepest layer로 갈수록 더 많은 정보를 포함하고 있다는 것을 확인할 수 있다.
또한 attention를 봤을 때 input에서 의미론적으로 중요한 부분에 더 집중하는 것을 확인할 수 있다.
we averaged attention weights of ViTL/16 across all heads and then recursively multiplied the weight matrices of all layers. This accounts for the mixing of attention across tokens through all layers.
Attention weight를 평균화하고, 다시 반복적으로 곱하면서 어느 부분에 집중하는 것인지 확인할 수 있다.

5. Conclusion
Image recognition에 Transformer를 적용한 사례이다.
Sequence of patch로 분할하여 적용하였다.
Large dataset에 좋은 효과를 보였다.
한계로는 detection과 segmentation task에 적용하기 어렵다. 그리고 self supervised pre training method에 대해 더 연구가 필요하다.
'논문 리뷰' 카테고리의 다른 글
[논문 리뷰] Generative Adversarial Nets - GAN (0) 2024.09.10 [논문 리뷰] Auto-Encoding Variational Bayes - VAE (1) 2024.08.27 [논문 리뷰]: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) 2024.08.05 [논문 리뷰] Attention is all you need - Transformer (1) 2024.07.28 [논문 리뷰] Sequence to Sequence Learning with Neural Networks - Seq2Seq (0) 2024.07.21