-
[논문 리뷰] Attention is all you need - Transformer논문 리뷰 2024. 7. 28. 14:59
[논문 링크]
[세줄 요약]
Transformer architecture의 출현
Multi head Attention을 사용하여 계산함.
병렬적으로 처리하여, 비용을 낮추고 긴 문장을 처리할 수 있게 됨.
[Abstract]
Transformer라는 new architecture를 제시함.
기존의 모델보다 더 병렬적으로 처리 가능하고, 학습하는데 소요되는 시간이 짧다.
[기존 모델의 문제점]
RNN 모델은 구조적으로 전의 hidden state에게 정보를 받아 sequence 대로 순서대로 정보를 처리한다. 이는 더 긴 Input(Longer sequence lengths)를 처리하는데 제약이 있다. 즉 병렬적으로 처리하지 못한다는 한계가 존재한다.
*병렬적: Input을 한번에 동시다발적으로 연산하는 것 <-> 순서대로 처리하는 것
Attention 구조는 RNN와 함께 사용하여 긴 input을 처리하는데 도움을 줬다. (이는 seq2seq + attention 를 사용하는 것을 말하는 것으로 보인다.)
Attention mechanisms allow modeling of dependencies without regard to their distance in the input or output sequences.
Transformer에서는 attention 모델만을 사용하여 전체적인 input과 output를 처리할 수 있도록 하였다.
[Model Architecture]
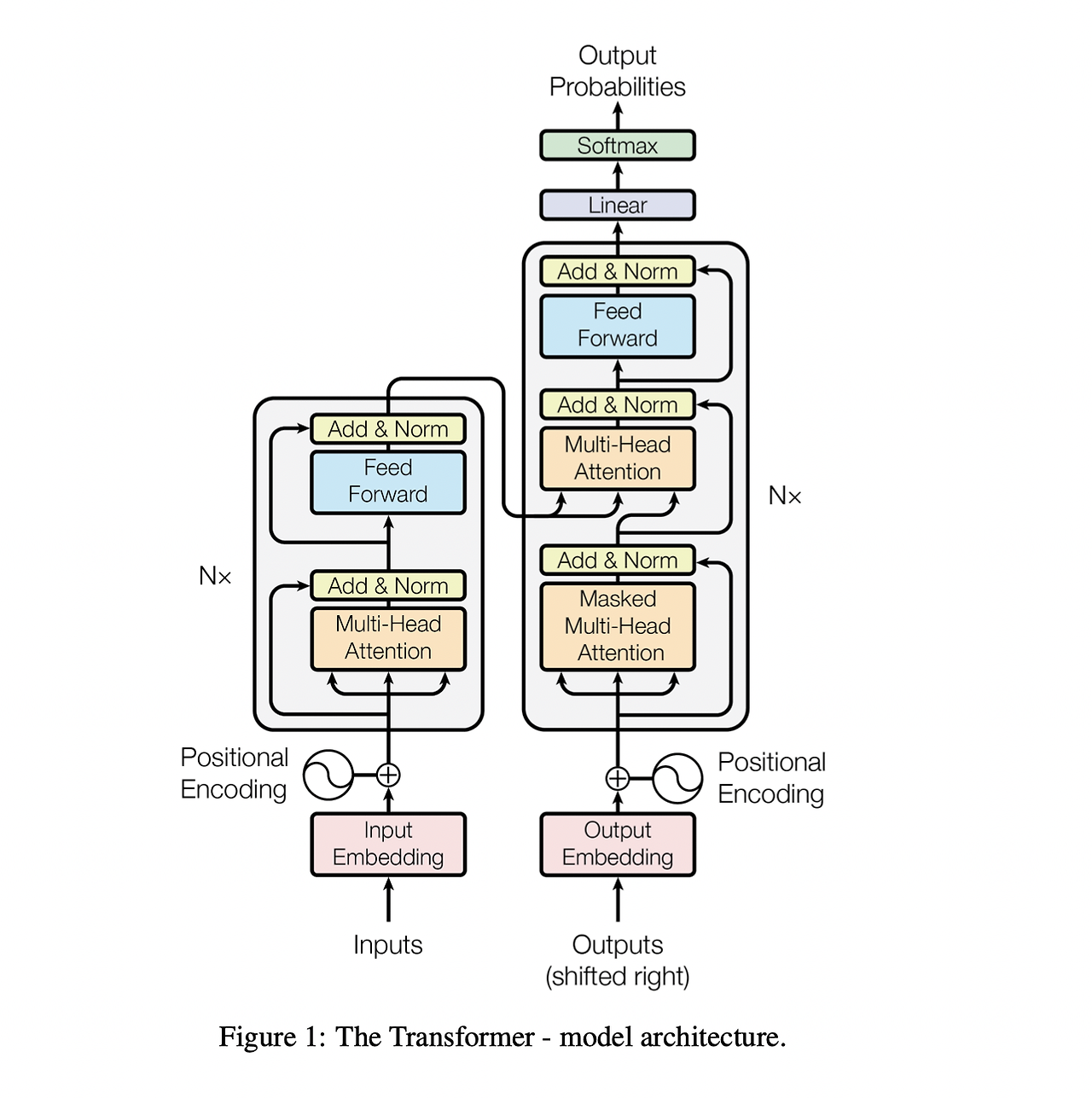
Transformer architecture이다. 하나씩 들어가보자. 이해를 위해 아래부터 천천히 올라가보도록 하자.
1) Encoder & Decoder
- Add & Norm
2) Attention
- Scaled Dot-Product Attention
- Multi-Head Attention
- Masked Multi-Head Attention
3) Position-wise Feed-Forward Networks
4) Embedding and Softmax
5) Postional Embedding
0.Encoder & Decoder
Transformer는 기본적으로 Encoder와 Decoder의 형태로 나누어져 있다. 복잡해보이지만 확인할 수 있듯이 사실 둘이 비슷한 구조이다. Mask의 차이, 그리고 Decoder에는 Encoder의 output를 받는 하나의 Sublayer가 있다는 것을 확인할 수 있다. 이는 후에 다시 설명하겠다!
1. Embedding
쉽다. Input에 sequence를 넣을 때, 각 단어의 embedding vector를 사용한다.
Sequence의 단어를 Token으로 변환시키고 이러한 Token에 해당하는 embedding vector를 사용한다.
ex) I love you. -> 3 2 1 (Tokenize) -> d차원의 embedding vector로 변환
Embedding vector의 크기는 d차원이다. (논문에서는 d = 512)
2. Postional Embedding
Attention 메커니즘은 병렬적으로 처리하기 때문에, 위치 정보에 대한 데이터가 없다.
A love B. 라는 문장에 위치정보를 포함하지 않기 때문에 B love A. 전혀 다른 의미를 포함하게 정보가 처리될 수 있다. 그렇기 때문에 attention에 넣기 전에 의미정보를 포함한 embedding vector를 넣어야 한다!

위와 같은 Sinusoid Positional Encoding 방법을 사용한다. 식을 보면 알 수 있듯이 sin과 cos를 사용한다.
*Postional encoding에 sin과 cos이 쓰인 이유
1) 위치벡터의 값이 기존의 의미 정보를 변질하지 않을 정도로 낮은 값이어야 한다.
2) 같은 위치에 있는 Token는 같은 위치벡터의 값을 가져야 한다.
후보1) 순서대로 벡터값 증가 ( w1: +1, w2: +2, w3: +3 ...)
문장이 길어지면 벡터값이 말도 안되게 커져서 의미정보가 퇴색된다.
후보2) n등분하여 추가 ( w1: +1/n, w2: +2/n, w3: +3/n)
문장의 길이가 다를 경우 같은 위치 벡터를 가지지 않는다.
후보3) sigmoid 함수의 값 추가
n이 너무 많으면 너무 촘촘해진다. 위치가 다르다는 것이 잘 안 나타난다.
=> 주기 함수인 sin를 사용하자!
sin만 쓰면 주기에 따라 중복될 수 있다.
sol1) 주기를 조절하자.
sol2) cos함수랑 같이 사용하자.
주기에 따라 더 다양한 위치정보를 포함하고 작은 값으로 embedding할 수 있다.
Postional encoding 예시 값)

이렇게 구한 postional encoding을 기존의 embedding vector와 합친다.
참고) Postional Encoding
트랜스포머(Transformer) 파헤치기—1. Positional Encoding (blossominkyung.com)
3. Attention
Attention 과정을 하나씩 살펴보자.

Scaled Dot-Product Attention
1. Query, Key, Value 값 생성

Postional encoding까지 한 embedding vector x에 각각의 Q,K,V의 Weight를 곱해서 각 단어의 q,k,v vector를 만든다.
2. query과 key를 내적하여 단어 간의 연관성을 나타내는 attention score를 계산(Matmul)
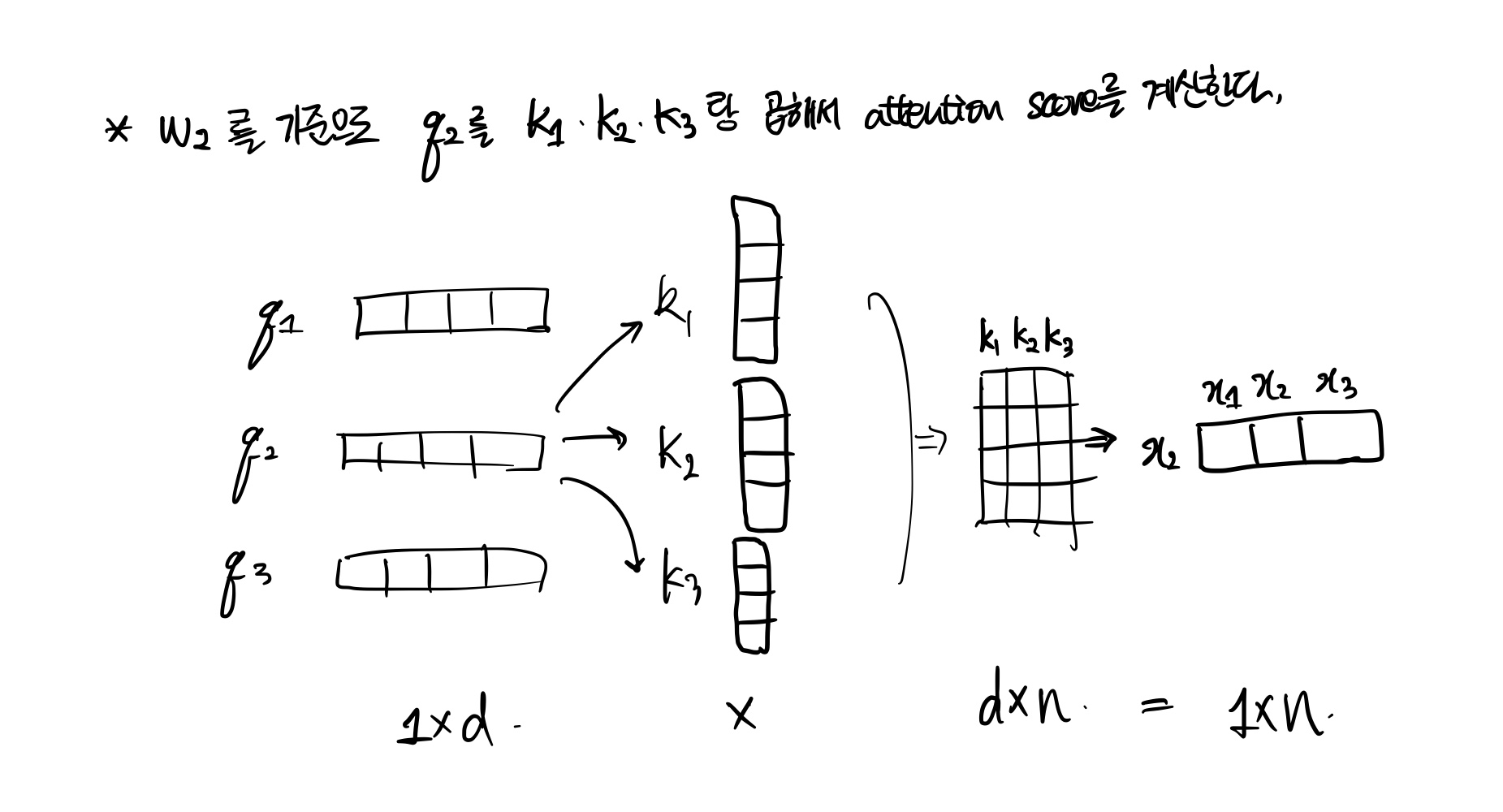
2번째 단어인 w2에 대해서 단어간의 관계를 파악하기 위해서 w1의 의미정보를 포함한 key1, w2의 의미정보를 포함한 key2, w3의 의미정보를 포함한 key3 벡터를 각각 내적하여 w2가 w1,w2,w3간의 의미관계를 포함한 벡터를 만들어낸다. 이렇게 만들어진 1xn vector의 값을 attention score 값이라고 한다.
3. \( d_{model} \) 로 나누어서 scale하고, softmax으로 정규화한 다음, value를 곱해서 의미정보를 추출한다.
(Scale, Softmax, Matmul)

후에 수식으로 다시 설명할 예정이다. 먼저 Attention score에 Dot product attention을 적용한다. 이는 차원을 나누는 것으로 값을 smoothing하는 의의가 있다. softmax을 적용하고 value vector를 곱해서 \( w_{2} \) 가 다른 단어들과의 의미관계를 포함한 벡터 값을 추출한다.
지금까지 하나의 단어 \( w_{2} \) 에 대해서 차원 정리를 한 것이다.
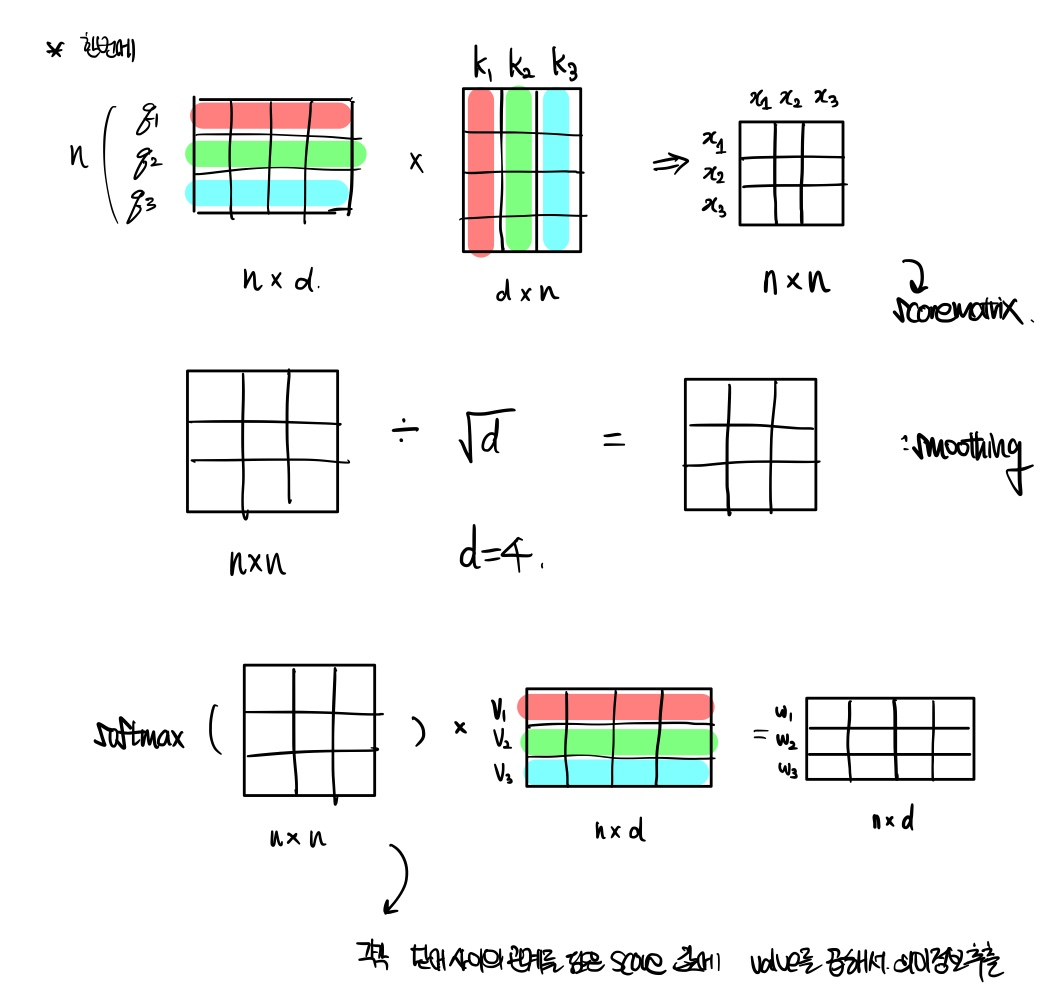
실제로는 다음과 같이 한번에 진행하게 된다.
Multi-Head Attention
Multi-Head Attention는 Weight \( d_{model} \) 차원을 쪼개서 여러 번 Scaled dot product attention을 진행하는 것이다.
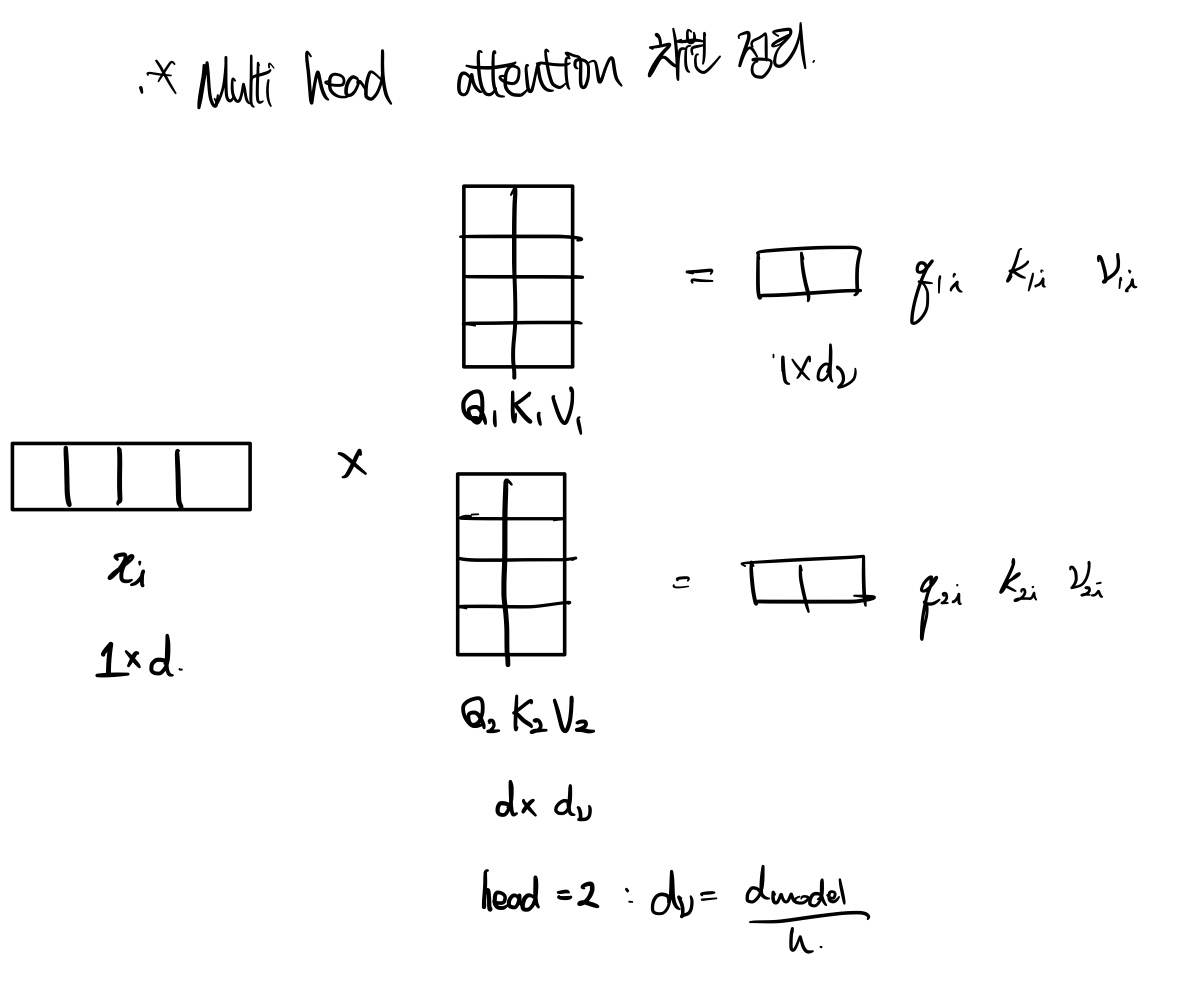
다음과 같이 head 수가 2일 때, 기존의 weight를 나눠서 각각 따로 q, k, v를 생성하여 계산하게 된다.
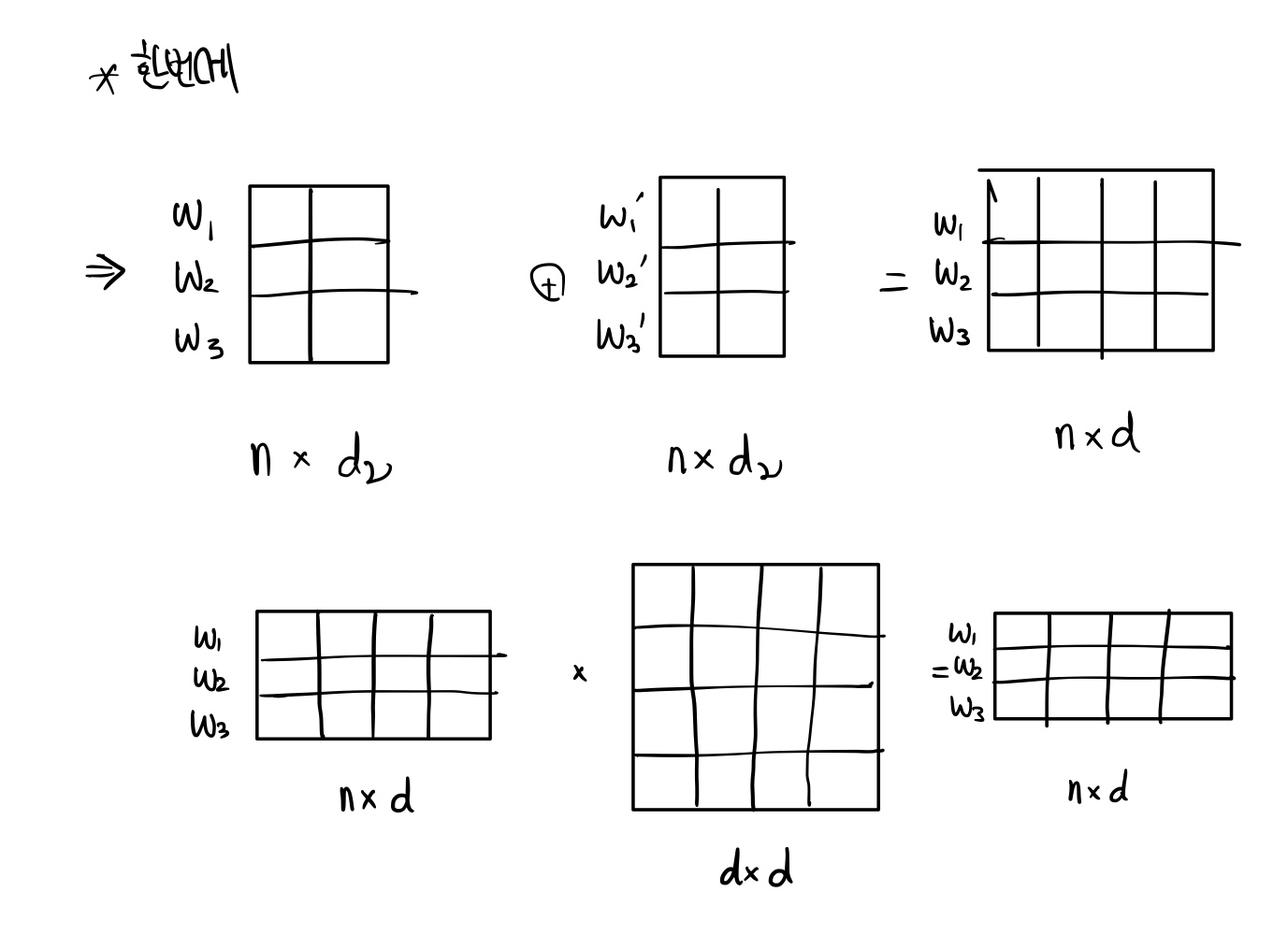
이렇게 각자 구한 output value를 concatenated한 후, linear를 하는 과정을 거친다.
Concatenate 하면서 쪼개진 차원은 다시 \( d_{model} \) 차원이 된다.
합쳐진 vector는 새로운 Weight를 곱하여 linear하는 과정을 거친다.
지금까지는 차원을 정리하여 개념을 익혔고, 수식을 보면서 다시 이해해보자.
Embedding + Postional Encoding

Embedding matrix을 곱하여 embedding vector를 만들고,
postional encoding한 값을 더한다.
Attention

query, key, value 값을 각 word embedding에서 weight matrix을 곱하여 만들어낸다.

key와 query를 곱하여 둘의 유사도를 계산한다. 내적하는 것은 단어 간의 관계를 나타나는 것이고, 관계가 비슷할 수록 내적의 값이 크게 나온다. transpose하는 이유는 차원을 맞추기 위함이다. 행렬곱의 원리를 생각해보면, 하나의 단어가 주변의 모든 단어와 내적하여 관계를 계산하는 원리를 알 수 있다.
Softmax하여 normalize을 진행한다. 그리고 output는 다른 단어와의 관계를 나타내는 attention score, 즉 가중치에 그 단어의 의미를 나타내는 value를 곱하여 출력한다.
Scaled Dot-product attention

위의 attention 작업에서 차원의 크기로 나누는 작업을 진행한다. 이는 전체적으로 smoothing하는 역할을 한다.
Multi Head attention

Concatenated한 후 Weight matrix을하여 linear하는 것을 확인할 수 있다. 논문에서는 \( d_{model} \) 는 512차원이고, 이를 head 8개로 나누어서 64차원의 weight matrix 차원을 사용하였다.
Multi head attention는 Encoder, Decoder, Encoder-Decoder 에 따라 다르게 적용된다.
1) Encoder
일반적으로 적용된다. q, k, v 다 같은 단어에서 유래된다.
2) Decoder
Masking하는 과정을 거친다. Decoder는 사실 미래의 정보를 가지고 학습하면 안된다. 예를 들어, I love you를 나는 너를 사랑해로 번역할 할 때, '너를'를 출력할 때는 '사랑해'라는 단어의 정보를 포함하면 안된다.
We need to prevent leftward information flow in the decoder to preserve the auto-regressive property.
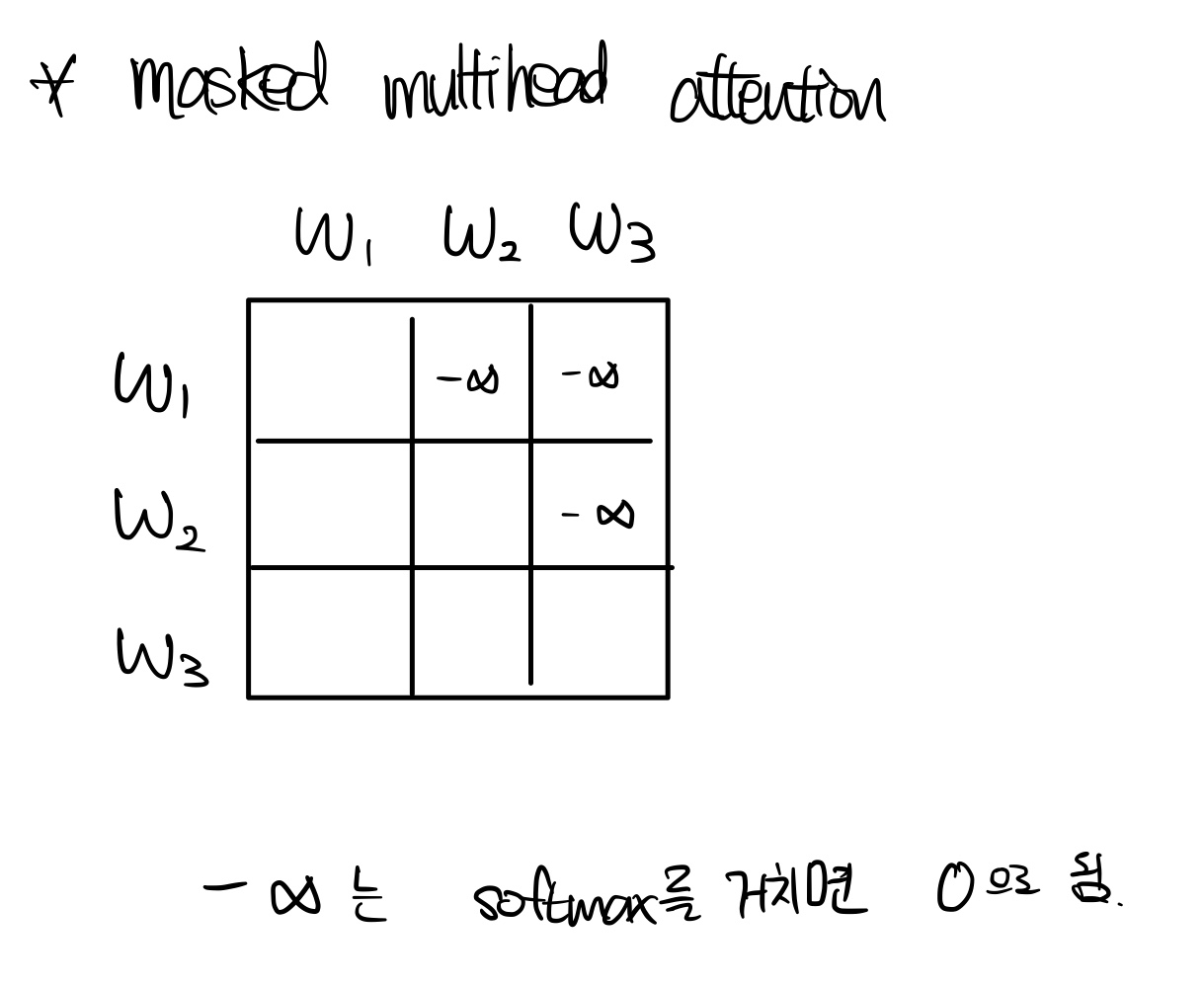
그렇다면 이를 어떻게 처리하나면, -무한대 값을 넣어 처리한다. 이는 Softmax을 거치면 0이 되어 의미정보에 관여하지 않게 처리할 수 있다. w2에 대해서는 w3의 단어를 -무한대 값을 넣는 것이다.
3) Encoder-Decoder attention
Encoder-decoder attention는 decoder layer에서 확인할 수 있다. 아키텍쳐를 다시보면 encoder에서 화살표 두개가 multi head attention으로 향하고, decoder에서 하나가 multihead attention sublayer로 가는 것을 확인할 수 있다.이는 Encoder에서 Key, Value 값이 오고, Decoder에서 query 값을 사용하는 것을 의미한다. 이는 마치 seq2seq + attention model과 유사하다.
나는 개인적으로 "key는 단어 사이의 관계 정보, value는 해당 단어의 실제 정보, query는 현재 계산하고자 하는 단어 정보" 로 이해하였다. 그렇기 떄문에 decoder에서 내가 계산하고자하는 단어인 query를 주고, encoder에서 지금까지 계산한 의미정보들인 key와 value를 준다고 이해하였다.
4. Position-wise Feed Forward Network

Feed Forward Network sublayer를 거친다. Attnetion 과정에서 선형적인 요소밖에 없는 것을 확인할 수 있다.

선형적인 요소만 계산하면 선형의 총합은 결국 하나의 선형으로 나타날 수 있다. 즉 self-attnetion의 layer를 여러 개 사용하더라도 사실 하나의 sub layer를 사용하는 것이랑 비슷하다는 것이다. 그렇기 때문에 비선형적인 요소를 첨가하기 위해 FFN layer가 추가되었다. FFN는 위의 수식에서 확인할 수 있듯이 ReLU 함수를 사용하는 것이다.이렇게 단순히 비선형적인 함수 추가를 통해 선형의 문제를 해결한다.
5. Add & Norm
Encoder, Decoder에서 각각의 sublayer(multi head attention, FFN)를 진행하고 Add&Norm layer를 계산하게 된다.
모든 layer의 output는 LayerNorm(x+Sublayer(x))를 거치게 된다. 이에 대해 하나씩 설명해보겠다.
Add: Residual connection

간단하다. layer 를 거치기 전의 값을 더하는 것이다.이로써 학습을 진행할 때 더 효율적으로 학습할 수 있도록 한다.
Normalization

다음과 같은 수식을 거치게 된다. 평균을 뺀 후, 표준편차로 나누어 normalizing을 진행한다. 이는 더 빠르게 학습하도록 한다. 입실론은 exploding을 방지하고 뒤의 감마와 베타는 gain과 bias이다.
[Why Self Attention]
Self Attention을 사용하는 이유는 크게 3가지이다.
1) Computational complexity per layer
2) Parallelized
3) Long range dependencies
즉 계산 비용이 적고, 병렬적으로 빠르게 처리할 수 있으며, 긴 문장들을 잘 처리한다는 것이다.
[Result]

영어번역 test에서 Transformer가 높은 BLEU score와 낮은 Training cost를 가진 것을 확인할 수 있다.

English constituency parsing test에서 또한 discriminative해도 좋은 점수를 받은 것을 알 수 있다.
'논문 리뷰' 카테고리의 다른 글