
[논문 리뷰]: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[논문 링크]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[세줄 요약]
BERT는 Deep bidirectional representation를 pretrain하는 모델이다.
Pretrain하는 방식은 2가지 방식 MLM(Masked LM)과 NLP(Next sentence Prediction)를 사용한다.
BERT는 Finetuning하여 좋은 성능을 보여줄 수 있다.
0. Abstract
BERT(Bidirectional Encoder Representations from Transformers)는 Pretrained(사전훈련된) 모델 중 하나이다. 레이블되지 않은 테스트로부터 Deep bidirectional Representations를 사전훈련하는 모델이다.
BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
이렇게 Pretrained BERT는 output layer를 추가함으로써 fine tune해서 다양한 task를 수행할 수 있다.
1. Introduction
Pretrained model는 BERT 전에도 여러 번 있었다. Pretrained language representation을 학습하는 방법은 크게 2가지 방법이 있다. Feature based approach, Finetuning approach 두가지이다.
1) Feature based approach: 대표적으로 ELMO
2) Finetuning approach: 대표적으로 OpenAI GPT
하지만 둘 다 Unidirectional language model이라는 한계가 있었다. BERT는 MLM(Masked language model)과 NSP(Next sentence prediction)를 통해 pretrain하였다.
BERT의 핵심은 Deep bidirectional한 학습을 했다는 것이다. Masked Language model를 통해 Deep bidirection representation을 학습할 수 있게 되었다. 기존의 bidirectional 한 접근은 단순히 left to right, right to left를 concatenation하였기 때문에 deep하다고 할 수 없다.
2. Related Work
Pretrained general language representation을 만드는 기존의 3가지 방식들이다.
1) Unsupervised Feature based Approach
ex) ELMo
Concatenation of the left to right and right to left representations
이러한 좌우방향의 단순한 feature를 추출하는 방식은 deep하지 않다.
2) Unsupervised Fine tuning Approach
ex) GPT
Unlabeled text로부터 pretrain하고, fine tune하여 downstream task를 수행하는 방식이다. 적은 parameter로 학습할 수 있다는 장점이 있다.
3) Transfer Learning from Supervised Data

3. BERT
BERT는 크게 2가지 단계로 나누어져 있다. Pretraining step과 Fine tuning step이다.
Pretraining step는 Unlabeled data를 학습하고, Fine tuning step는 labeled data를 학습한다. Fine tuning step에서는 pretrained된 parameter를 가지고 각 downstream task에 맞춰서 학습한다.
1) Model Architecture
BERT는 multi-layer bidirectional Transformer encoder 이다. 기본적으로 Transformer의 Encoder형태를 띠고 있으며, 여러 layer를 가지고 있다.
BERT base: Layer =12 Hidden size=768 Self-attention heads=12 총 1억1천만 파라미터
BERT large: Layer =24 Hidden size=1024 Self-attention heads=16 총 3억4천만 파라미터
BERT base model이 OpenAI GPT과 파라미터 수가 똑같다. BERT는 bidirectional self attention인 반면에, GPT는 left에서만 받을 수 있는 self attention이다.
Input/Output Representations
Input = Token Embedding + Segment Embedding + Position Embedding
1) Token Embedding:
WordPiece embedding을 사용(30000 token vocab)
2) Segment Embedding:
2개의 문장(sentence A, B)을 input을 사용하게 되는데, sentence A일 경우 A라고 embedding하고, sentence B일 경우 B라고 embedding한다. 간략하게 말해서 embedding는 무슨 문장의 token인지를 지칭한다.
3) Position Embedding: transformer와 동일하다.
여기서 추가로 봐야할 점은 [CLS]과 [SEP]이다.
[CLS]
Input 맨 앞에 들어가는 token 이다. 이는 hidden state를 거친 후 문장 자체를 표현하여, classification task 같은 경우 사용하게 된다. 즉 이 token는 input sequence 그 자체를 representation하는 token이다.
[SEP]: Special separator token
이 Token는 문장을 구별하는데 사용된다. 문장 사이에 이 token이 들어간다.
2) Pretraining BERT
MLM과 NSP를 통하여 pretrain하였다.
1) Masked LM (MLM)
단순히 left to right과 right to left를 concatentation하는 얕은 model이 아니라 deep 모델을 만들기 위한 task이다. Deep bidirectional representation을 학습하기 위해 MLM를 사용한다.
이는 일정 비율의 input token를 [MASK]하여 이를 예측하게 하게끔 학습시키는 것이다. 15%의 단어를 mask할 때 가장 성능이 좋았다.
Mask token를 random하게 학습하는 것의 단점은 pretrain model과 fine tune model의 mismatch가 발생하는 것이다. 왜냐하면 pretrain model의 경우 [MASK]을 학습하지만 fine tuning model의 경우 [MASK] 가 없기 때문이다.
이를 해결하기 위해 [MASK] token에 추가적으로 변화를 준다.
1) 80%의 경우 [MASK] token을 그대로
ex) my dog is hairy → my dog is [MASK]
2) 10%의 경우 random 단어로 바꾸고
ex) my dog is hairy → my dog is apple
3) 10%의 경우 원래 단어 그대로 유지한다.
ex) my dog is hairy → my dog is hairy.
이렇게 [MASK] token에 변화를 줄 경우 transformer encoder는 어떤 단어가 예측해야되는 단어인지 특정화하지 못하기 때문에 모든 input token에 대해서 학습을 실시하게 된다.
it is forced to keep a distributional contextual representation of every input token.
논문에서는 여러 가지 경우의 수를 실시해서 비율과 성능을 비교해준다.
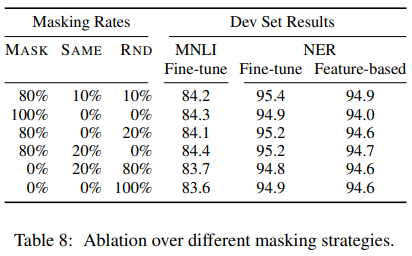
80%,10%, 10%일 때 가장 성능이 좋은 것을 확인할 수 있다. 10%의 양은 전체 sequence의 15%의 10%이므로 이정도 크기의 단어의 수는 model이 문장을 이해하는데 영향을 끼지치 않는다고 한다.
2) Next Sentence Prediction (NSP)
QA, Natural Language Inference와 같은 task를 수행하려면 두 문장 사이의 관계를 파악할 줄 알아야 한다. 이를 위해 Binarized Next Sentence prediction task를 수행하였다. 두 문장을 선택할 대, 50%의 경우에는 실제로 다음 문장을 선택하여 IsNext라고 label하고, 50%의 경우에는 random 문장을 선택하여 NotNext라고 label한다. [CLS]가 hidden state를 거친 C vector를 NSP에 사용한다.
즉 두 문장이 input되었을 때 이것이 이어진 문장인지 예측하는 vector C를 IsNext와 NotNext라고 label해서 학습한다.
ex)
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
Pretraining data: BooksCorpus(800M words), English Wikipedia(2500M words)
3) Fine-tuning BERT
Task에 따라 input을 넣어서 fine tuning한다.
1) Paraphrase: sentence pairs
2) Entailment: hypothesis-premise pairs
3) Question answering: Question-passage pairs
4) Text classification, sequence tagging: degnerate text-none pairs
Task에 따라 output도 다르다.
1) Sequence tagging or Question answering: token representation
2) Classification, entailment: [CLS]

(a)(b): Sequence level task
(c)(d): Token- level task
4. Experiments
GLUE, SQuAD v1.1, SQuAD v2.0, SWAG 등 여러 NLP task를 진행하여 성능을 비교하였다.
