[논문 리뷰] Distributed Representations of Words and Phrasesand their Compositionality - Word2vec
[논문 링크]
Distributed Representations of Words and Phrases and their Compositionality
[세줄 요약]
Negative sampling : 이진법 + noise 추가 => 이를 통해 training speed를 낮춤
Word2Vec을 통한 distributed representations이 선형적 구조를 띠는 이유를 objection function에서 확인할 수 있음.
Pharse도 표현할 수 있게 됨
[Abstract]
Continuous Skip gram model에 Negative sampling을 적용하여 Word2Vec의 quality과 training speed를 향상시킴.
Word뿐만 아니라 Pharse 학습에도 vector를 표현할 수 있게 됨.
[기존의 Skip-gram이란?]
간단히 말해서 중심단어(center word)를 통해 주변 단어(context word)를 예측하는 architecture이다.
Continuous skip-gram model에서는 Basic Softmax를 사용하였다. 논문에서는 Hierarchical Softmax를 사용한 약간 발전된 형태를 보여주기는 하지만 쉬운 이해를 위해, naive한 softmax를 사용한 것을 기존의 skip-gram이라 말하겠다.
[기존의 Skip-gram의 단점]
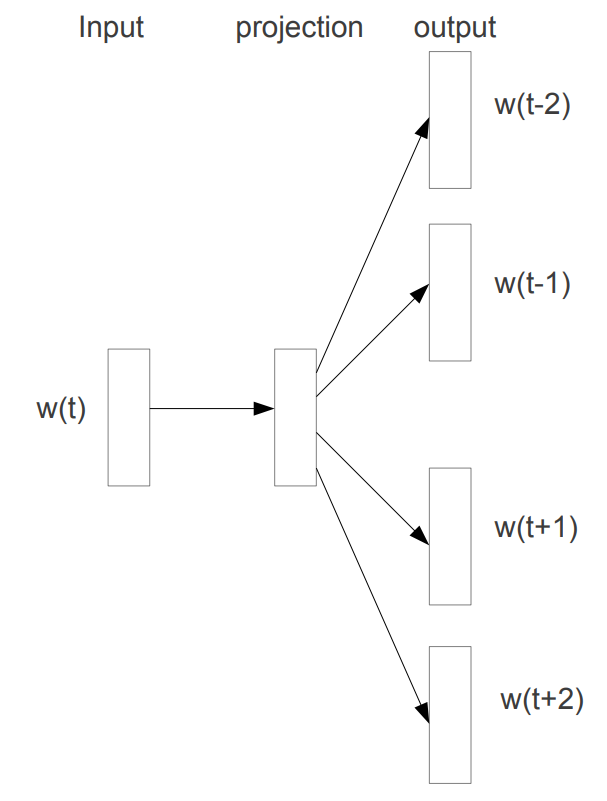
모델을 보면 center word의 one hot vector를 통해 context 단어를 예측하기 위해서 예측된 vector랑 실제 context word의 one hot vector를 비교하여 가중치를 학습한다. 이 때, 모든 단어에 대한 가중치를 학습하게 된다. 중심 단어랑 관련이 있는 단어일 경우 주변 단어(정답이니까) 가까워지기 위해 학습을 진행하겠지만, 중심단어랑 아예 관련 없는 단어일 경우 학습을 진행하더라도 유의미하게 변화가 일어나지 않을 것이다. 그렇지만 모든 단어에 대한 학습을 진행하기 때문에 training speed가 떨어지게 된다.
ex) cat이 center word일 경우 cute, love 같은 단어는 학습이 이루어지겠지만, computer 같이 뜬끔없는 단어의 가중치까지 학습할 필요는 없을 것이다.
[Skip-gram model 수식 이해]
Skip-gram model의 다음과 같은 (average) log probability를 maximize하는 것을 목적으로 한다.

똑같은 식을 다르게 objective function의 형태를 표현하자면 다음과 같이 표현할 수 있다.

objective function는 Negative log likelihood 형태로 표현되었다.
식에 대해 더 들어가자면,
c: training context의 size
T: 단어의 수
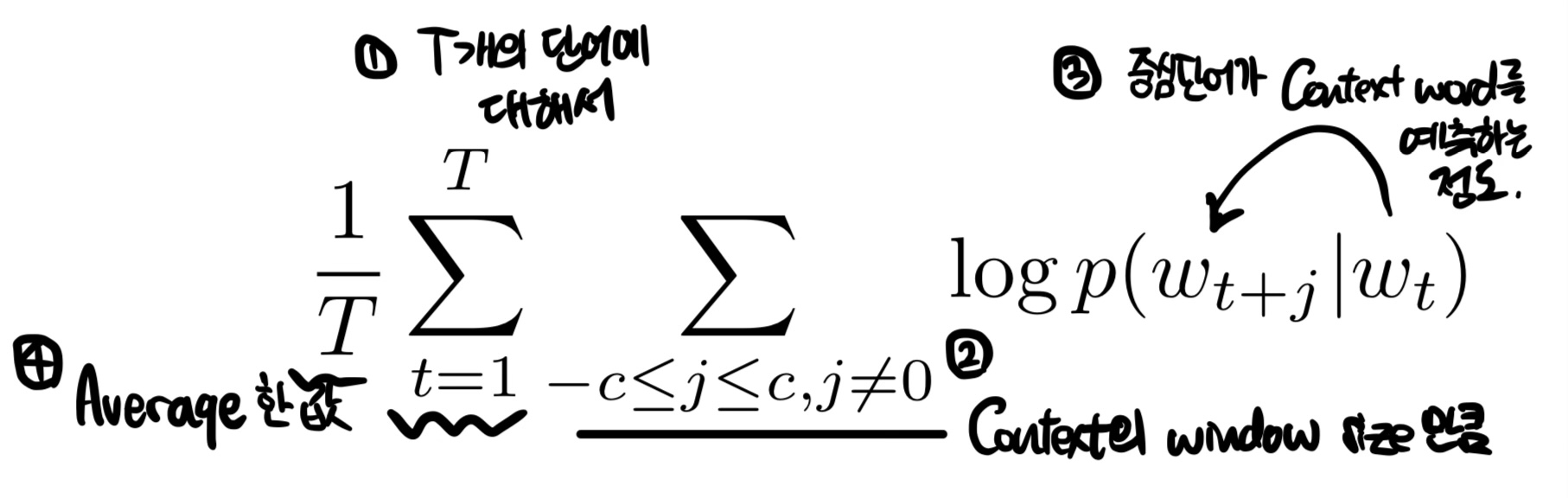
T개의 단어에 대해서 Context의 window size만큼 centerword가 context word를 예측하는 정도를 log를 취하고 합한 값을 average한 것이다.
즉 context word를 예측한 정도를 나타내는 식이므로, 당연하지만 Max가 될 수록 좋은 것이다.
클수록 예측하는 정확도가 높은 것 = Objective function이 낮을 수록 좋다 라고 표현할 수 있다.
그렇다면 P(contextㅣcenter) 는 어떻게 표현할까?
이는 Softmax function을 이용하여 표현한다.

일단 헷갈리는 부분이 하나 있다.
하나의 단어 w에 대해서 주변 단어일 때의 context vector v'와 중심단어 일때 center vector v가 존재한다.
굳이 한 단어에 대해서 상황에 따라 vector를 나눌 필요가 있을까 했는데, 계산의 편의성을 위해서 만들었다고 한다.
그리고 최종 word vector는 context vector와 center vecotr의 합 또는 평균을 사용하여 처리한다.
수식으로 들어가자면,
분자: context word(실제 context word일때)와 center word의 내적값
분모: 모든 단어와 center word의 내적값
으로 context word와 center word의 내적값이 클수록, context word가 나타날 확률이 크다.
exp 함수는 내적값을 양수화하고, 이러한 분자 분모 형태의 softmax 형태는 이 값을 정규화한다.
여기서도 확인할 수 있지만, 분모에서 모든 단어 W에 대해서 center word과 내적값을 계산해서 확률을 계산하는 것을 확인할 수 있다. W의 값이 클수록, 즉 단어의 수가 많을 수록 computing cost가 비례하여 커지는 것을 확인할 수 있다.
[Negative sampling]
Word2Vec에 Softmax 대신에 Negative Sampling을 도입하여 training speed를 단축하고 vector의 quaility를 올렸다.
Negative Sampling는 크게 2가지 아이디어를 사용한 것이다.
1) 이진법
2) Noise 추가하기(Negative sample 추가하기)
논문에는 Negative sampling 전에 기존의 방식 중 Hierarchical Softmax를 사용한 것도 설명하는데, 이는 이진법만을 사용한 느낌이다.
Negative sampling는 center word를 통해 context word를 예측 할때, context word(정답 단어들)는 1(정답)으로 레이블하고, negative sample(틀린 단어들)는 0(오답)으로 레이블해서 예측된 값과 label된 값의 오차를 비교하여 학습하는 것이다.
쉽게 말해, center word과 모든 단어를 비교하는 대신, 정답단어(context word)와 몇개의 random word(negative sample)를 추가해서 비교하고, 비교할 때 이것이 정답이면 1, 오답이면 0 인 이진법적 구조로 판단하는 것이다.
center word vs context word(실제로 주변에 있는 단어) -> label 1
center word vs negative sample(random word)-> label 0
예시를 통해 설명하자면,
The cute cat sit on the floor.
center word: cat
context word: The, cute, sit, on (window size:2) -> label 1
random word: pizza, seoul -> label 0
cat의 embedding vector x cute의 embedding vector 의 예측 정도가 1에 가깝게,
cat의 embedding vector x pizza의 embedding vector의 예측 정도가 0에 가깝게 학습하는 것이다.
Negative sampling의 objective funtion은 다음과 같다.
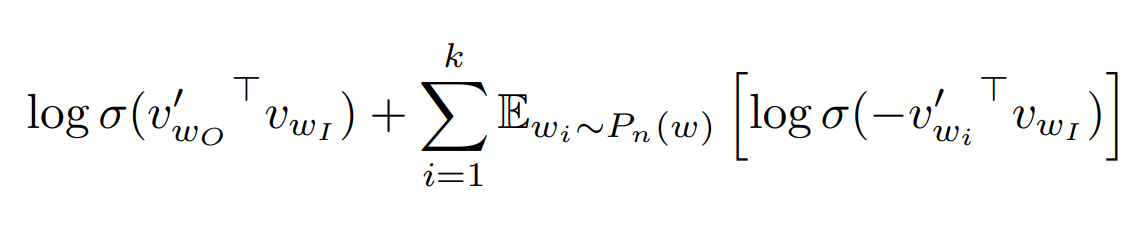
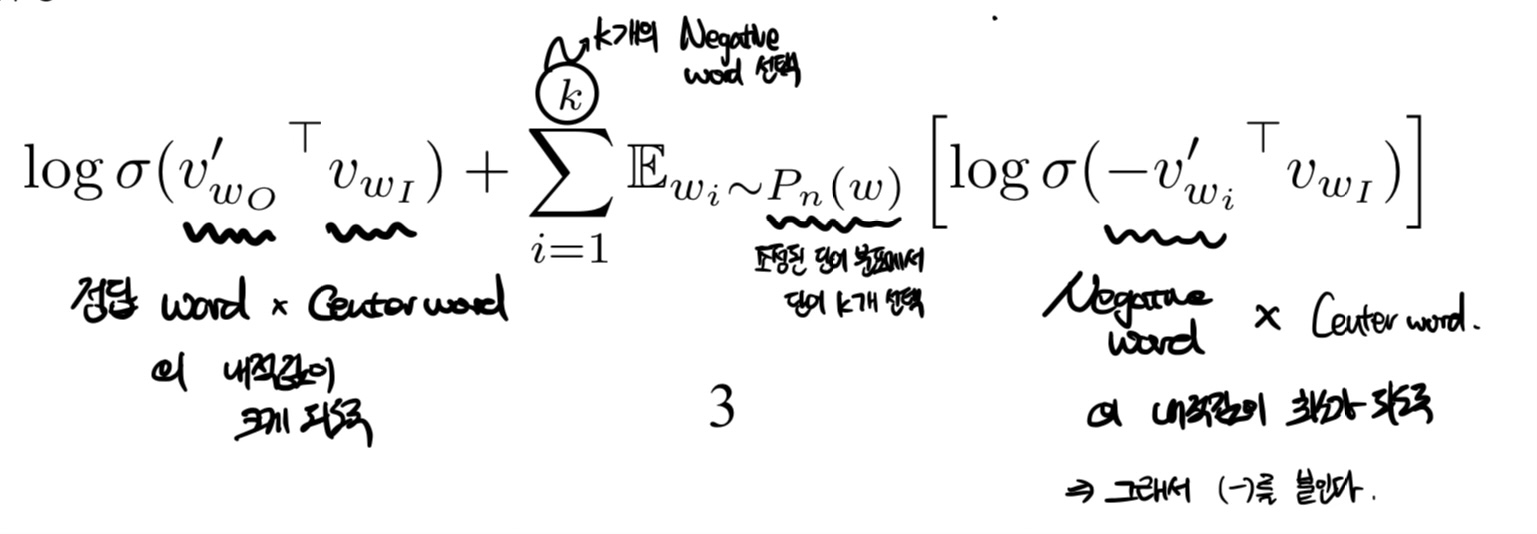
앞쪽은 정답 word과 center word의 내적값이 크도록 학습하고,
뒤쪽은 Random word과 center word의 내적값이 작도록 학습하는 것이다.
sigmoid function을 활용하여 값이 1에 가까워지도록 설정한다.
k: Negative word를 선택하는 갯수로 small training datasets에서는 5~20, large datasets에서는 2~5로 설정한다.
Pn(w): 조정된 단어 분포, unigram distribution에서 비롯된 조정된 단어분포이다.

보통 확률분포는 이렇게 조정된다. 3/4 승을 하면서 빈도가 높은 단어의 수를 줄여 다양성을 더 확보할 수 있다.
여기서 f(w)는 단어의 빈도이다.

sigmoid 함수 안의 값이 커질수록 log 값은 0에 가까워지기 때문에 결국 context word과 내적값이 클수록, random word과의 내적값이 작을수록(-) objection function의 값이 작아진다.
[Subsampling of Frequent Words]
in, the, a와 같은 단어들은 정보에 의미는 없지만 매우 빈번하게 나타난다. 이러한 단어들이 학습할 때 영향을 주지 않도록 흔한 단어의 비중을 줄여야 한다. 예를 들어 France와 Paris의 유사도가 France와 the랑 같다고 하면 이상하다. the가 france랑 같이 붙긴하지만 이러한 co-occurrence가 모델 학습에 긍정적인 영향을 주지 않는다.


즉, f(wi) 단어의 빈도가 높을 수록, sampling되는 확률을 줄인다.
t: 역치값, 주로 10의 -5
ex) the의 빈도가 = 0.1 처럼 매우 높다. -> P(w) = 0.99 이므로 100번 중 99번은 제외하는 것이다.
[Learning Phrases]
단어뿐만 아니라 구,pharse를 학습한다.

bigram으로 선택할지, unigram으로 선택할지 결정한 후, 하나의 구로 선택할 시, unique token을 따로 부여하는 방식으로 진행하였다. 위 식은 wi, wj로 이루어진 pharse의 빈도가 역치값을 넘을 시 unigram으로 결정하는 수식이다.
[Result]

syntactic, semantic test를 진행하였는데, NEG(Negative sampling with k negative samples) + subsampling 할 때 정확도가 가장 높은 것을 확인할 수 있다.
[Additive compositionality]
Word vector가 선형적인 관계를 가진 것을 알 수 있다. 이는 Vector의 합과 뺄셈을 통해 의미적인 구현이 가능하다는 것이다. 이는 contex(의미적 표현)의 외적, 곱이 log로 나타나졌을 때, vector의 합으로 표현할 수 있기 때문에 이러한 vector representations을 가지게 된다.
[참고]