-
[CN 스터디] Ch2: Modeling Neural Circuits Made Simple with Python카테고리 없음 2025. 2. 3. 01:21
1.3 Modeling Synapses
Ionotropic synapes
current-based synapse model - currents are generated directly from presynaptic spike times
conductance based synapse model - appendix B.3 더 detailed
Dale's Law: presynaptic neuron는 post synaptic neuron과 같은 타입의 synapse를 가진다.
excitatory and inhibitory
80% excitatory neuron - 대부분 pyramidal neurons
20% inhibitory neuron - interneurons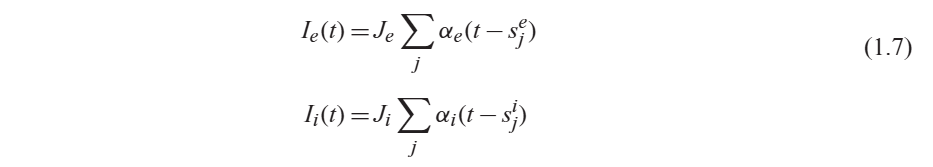
I: 전류값
J: 시냅스 가중치 excite > 0, inhibit < 0
alpha: PSC waveforms
s: presynaptic spike time
alpha의 조건
1) a(t): PSC의 시간적 형태를 나타냄
2) t<0 일 때 alpha = 0
3) 적분 값이 1 => 정규화를 위해

다음과 같은 PSC 파형 모델 식을 세우게 된다. - Exponential Synapse Model 임.
Simulate를 위해 Dirac delta function으로 표현함.

*Dirac delta function이란?
특정 점에서 무한히 큰 값을 가지며 전체 넓이가 1이 되도록 정의된 분포로, 함수의 특정 값을 추출하거나 물리적 특이점을 모델링하는 데 사용.


수식 1.7을 간단히 한 식.
S: spike density
Spike density란, Spike라는 이벤트를 기록한 Spike Train에서 델타함수를 적용하여 연속적인 시간 함수로 변환한 것.
Spike Train: 뉴런이 발화한 시간들의 나열. - 이산적임.
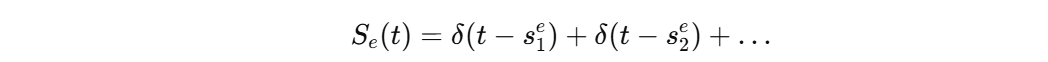
이런 식으로 spike이 일어난 시간으로 이루어진 dirac 델타 함수를 적용할 수 있다.
연속적인 시간함수가되면서 컨볼루션을 적용할 수 있음.

# Binarized presynaptic spike train, Spike density로 변환 Se=np.zeros_like(time) Si=np.zeros_like(time) Se[np.floor(ExcSpikeTimes/dt).astype(int)]=1/dt Si[np.floor(InhSpikeTimes/dt).astype(int)]=1/dt #Euler solver to compute Is and V for i in range(len(time)-1): V[i+1]=V[i]+dt*(-(V[i]-EL)+Ie[i]+Ii[i]+Ix[i])/taum Ie[i+1]=Ie[i]+dt*(-Ie[i]+Je*Se[i])/taue Ii[i+1]=Ii[i]+dt*(-Ii[i]+Ji*Si[i])/tauisimulation 동안 원하는 PSP를 그리기 위해서는 timescales -> time constant -> synaptic weights 순서로 수정.
2. Measuring and Modeling Neural Variability
2.1 Spike Train Variability, Firing Rates, and Tuning
Neural Variability: Irregularity of spike가 존재함.

Binarized spike train: 2ms time window로 사용하면 interval이 짧기 때문에 1 spike or zero spike으로 이분화 할 수 있음. 이는 firing rate 계산할 떄 유용하다.
Firing rate: number of spikes per unit time, spike/s -> Hz 단위

Cortex Neuron - spike 1-50Hz.
Firing rate 그래프가 불연속적임. 연속적으로 만들기 위해 overlapping time intervals을 사용함.

다음과 같은 kernel를 사용해서 smoothing 함. 주로 Gaussian kernel 사용함.
r(t): time-dependent firing rate
설명: S(t)(spike density)로 표현된 식은 delta function으로 이루어진 discrete한 데이터다. 뾰족한 모양.
k(t)를 Gaussian kernel 이자 적분 값이 1인 함수로 정의한다.

t: time, sigma: 표준편차
-> convultion 시 spike 발생한 시간 근처에서 부드럽게 값이 퍼짐.
#Gaussian kernel k = np.exp(-s**2 / (2 * sigma**2)) k = k / (np.sum(k) * dt) # Normalize kernel #Convolution SmoothedRate = np.convolve(S, k, mode='same') * dtDataset: SpikeTimes1Neuron1Theta.npz
- monkey visual cortex
- drifting grating stimulation for 1s
- trial 200번
- theta: 자극의 각도
Spike Density Array로 쉽게 데이터 저장
skj: k번쨰 실험, J 번째 spike
그렇다면 S[k,:]는 k번째 trial의 spike density가 저장되게 된다.
S = np.zeros((NumTrials, len(time))) # Spike Density Array 초기화 S[TrialNumbers, (SpikeTimes/dt).astype(int)] = 1/dtFano factor: Trial variability를 측정, ratio btw 분산과 평균

FF=0 neuron이 똑같이 spike
FF>1 trial to trial variability가 크다.
Orientation tuning in primary visual cortex
receptive field: 자극에 반응하는 region
orientation의 angle에 따라 firing rate이 증가함. - highest firing rate = preferred orientation
하나의 neuron보다 neuron 집단을 통해 분석.
2.2 Modeling Spike Train Variability with Poisson Processes
Spike train variability: 똑같은 자극을 주더라도 spike의 시간적인 변동성이 존재
How to model spike timing variability?
=> Stochastic process: 시간에 따라 상태가 랜덤하게 변화
그 중 Point process: 불연속적으로 발생하는 사건.
Counting Process: n(t): t 시간 동안 spike의 갯수.

Instantaneous firing rate: 즉시 발화율

r(t): 시간 t에 뉴런이 발화할 확률, 단위 시간동안 스파이크 발생의 기대값.
정의)
1. E[N(t,t+ δ )] : 시간 t 근처에서 발생하는 스파이크 개수의 기댓값
이를 시간 구간으로 나누므로 단위 시간 당 발생하는 스파이크의 기대값이 된다.
2. 미분으로 표현:
E[n(t)]: t시간 까지 발생한 스파이크의 총 갯수의 기대값
이를 미분하면, 누적된 스파이크 기대값의 시간 변화율
3. Spike density로 표현
S(t): 특정 시간 t에 스파이크가 발생했는지 여부를 표현
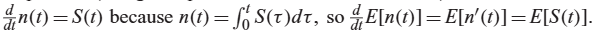
직관적 이해 d/dt n(t) = S(t)
n(t): 시간 t까지 누적된 스파이크의 갯수 / S(t): 특정시간 t에서 발생한 스파이크

1) 시간 구간 [a,b] 동안 뉴런이 발생시킬 스파이크의 평균 갯수
2) 특정 시간 t에서 뉴런이 발화할 즉시 발화율을 시간 구간 [a,b] 에 대해 합산
r(t) 단위 Hz: spike 수 / s : 단위 시간 동안 발생하는 평균 스파이크 갯수.
dt : 시간을 곱함. => 총 spike의 갯수.
참고) 이해: 단위 시간 동안 발생할 스파이크의 평균 갯수 또는 강도, t = 0.1 => 0.1초 때 강도, 발화 확률.
Stationary process : 정적 특성일 경우
Definition: N(a,b) = N( a+t, b+t )
Theorem. r(t) = r , E[n(t)] = rt
r(t)가 일정하지만, 스파이크 간의 상관관계는 있을 수 있음.
ex)

Homogeneous Poisson process (Stationary Poisson process)
:stationary point process + memoryless property.
:스파이크 발생이 독립적, 시간 구간마다 독립적
: spike는 어느 시간 분포에 있어도 동일하게 발화함.
: n(t)가 푸아송 분포를 따름.

*포아송 분포: 어떤 사건(spike)가 몇 번 발생하는지를 나타내는 확률 분포
n: spike가 발생한 이벤트 갯수 r: 평균 발생률
n(t)의 분산과 평균이 같다.
즉 평균적으로 rt만큼 스파이크가 발생한다고 이해할 수 있다.
Fano factor = 1, trial to trial variability의 기준선.
subPoisson: FF<1
superPissson: FF>1
Poisson process를 생성하는 2가지 algorithm
1. spike times를 직접적으로 생성
N=np.random.poisson(r*T) SpikeTimes=np.sort(np.random.rand(N)*T)포아송 분포에서 스파이크 총 갯수를 생성하고
이를 시간에 랜덤하게 생성하여 순서대로 정렬 #0과1 사이의 난수를 생성
2. spike density를 생성
S=np.random.binomial(1, r*dt, len(time))/dt단위 시간내 스파이크가 발생할 확률을 총 시간 동안 시행하여 스파이크 발생 여부를 구함. (0,1로 이루어진 배열)
r*dt 의 값이 작아야 함. - 스파이크 발생이 2번 되는 것을 방지하기 위해서이다., *푸아송 정의 때문?
Spike density <-> Spike time switching
SpikeTimes=np.nonzero(S)[0]*dt S=np.zeros_like(time) S[(SpikeTimes/dt).astype(int)]=1/dtMultiple i.i.d. trials
Nonstationary spike trains(inhomogeneous Poisson process)
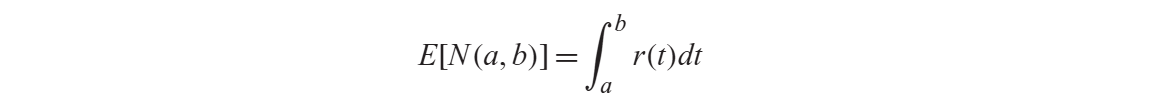
stationary 에서 r(t)가 시간에 따라 변화하는 특성으로 확장하는 것.
Inhomogeneous Poisson Process Algorithm: algorithm 2를 일반화.
r=(20+16*np.sin(2*np.pi*time/200))/1000 S=np.random.binomial(1,r*dt,(NumTrials,len(time)))/dtr*dt, r(t)*dt로 시간에 의존하는 단위시간에 스파이크가 발생할 확률을 사용함.
dt가 매우 작아야함.
Q. dt로 나누는 이유: 0,1로 이루어진 이진 행렬에서 dt로 나누어야지, 단위 시간당 스파이크(S(t))로 표현할 수 있음.

Q. r(t)*dt를 사용하므로써 시간에 따라 달라진 확률을 구할 때, np.random.binomial로 결국 그것에 따른 이진 행렬로 나타나게 되면, spike density를 표현할 때 확률적인 의미가 퇴색되는 것이 아닌가?
Figure2.4

A, B: r(t) = 15Hz : Homogeneous Poisson process
C, D: r(t) = 시간에 따라 변화하는 주기함수: inhomogeneous Poisson process
Exercise 2.2.1
import numpy as np #Fano_factor 계산 def ff(spike_counts): return np.var(spike_counts) / np.mean(spike_counts) #변수 r=10/1000 # Rate in kHz T=1000 # Time interval length dt=.1 # Discretized time time=np.arange(0,T,dt) # Generate 10 Poisson processes for _ in range(5): S = np.random.binomial(1, r * dt, (10, len(time))) spike_counts = S.sum(axis=1) # Sum spikes across time for each trial fano_factor = ff(spike_counts) print(fano_factor)2.3 Modeling a Neuron with Noisy Synaptic Input
- K개의 흥분성, 억제성 뉴런로부터 신호를 받는 single EIF modeling


여러개 시냅스로 적용한 식
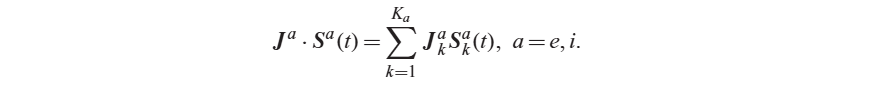
- r 값이 inhomogenous 한 것처럼, J 값도 일정하거나 inhomogenous할 수 있음.
- K x r 는 집단 전체에서의 평균 스파이크 발생 빈도라고 볼 수 있음.
Stationary mean values
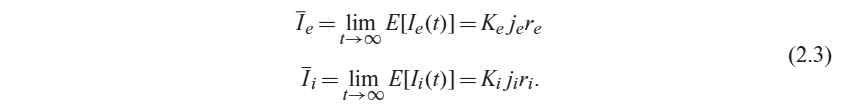
- 결국 정류값으로 수렴한다는 의미
- tau 보통 5ms로 작음- figure 2.5 ce 에서 장기적인 평균선임.
- E[J*S] = J * r = K * j * r
Mean-field theory

- 결국 같은 말. noise가 있어도 T가 무한으로 가면 평균 전류값으로 수렴한다.
- V(t)는 non linar하기 때문에 mean field theory를 적용하기 쉽지 않음.

- 정류값과 noise의 input으로 EIF가 도출되는 식으로 표현 가능함
Noise driven or fluctuation-driven spiking
- EIF에서 정류값 I = 12.75mV, Vth = 15mV 이면 원래 spike가 안됨
- noise 때문에 spike가 가능해짐

- Vo : free memebrane potential
- active current과 spike를 제외한 막전위
- 선형 방정식 형태
- mean-field approach 적용하기 쉬움

-stationary mean free membrane potential는 위와 같음.
fluctuation vs drift-driven regimes
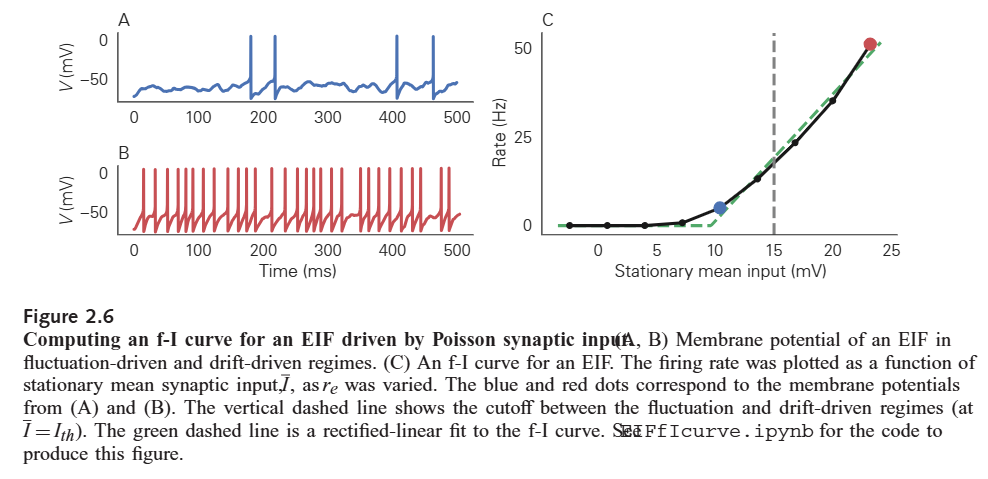
- drift driven: more regular spike, mean input에 의해 발화
- fluctuation: irregular spike
- f-I curve: firing rate / I정류값: 파란색 점이 fluctuation 지점.
- 점선 기준 왼쪽은 noise driven, 오른쪽은 drift driven
- I의 값에 좌우되는 것이 아니라 j와 r의 값에 의해 바뀜.
- 하지만 I가 큰 영역에서는 r에 대한 함수로 근사할 수 있음.
- K: 뉴런 갯수, j: 시냅스 가중치 r: 발화율
Mean-field synaptic weight

- 즉 이렇게 정리할 수 있다. w는 전체 시냅스의 가중치라고 이해하면 됨.
- 여기서 f 함수는 rectified linear function를 사용함.
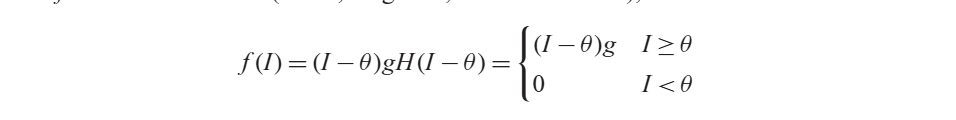
- H는 계단 함수 Heaviside step function이다.
- 세타: 발화가 시작하는 threshold
- g: gain 곡선의 기울기